Multi-Region Topology Design
The foundation of blockchain high availability is distributing consensus nodes across failure domains. For Fabric’s Raft consensus, you need at least 3 of 5 orderers alive to maintain quorum. ClearPort places 3 orderers in London (primary), 1 in Frankfurt, and 1 in Singapore, ensuring that London alone holds quorum while any two nodes across the network can fail without losing consensus. Peer nodes are distributed similarly, with anchor peers in London and Frankfurt serving active traffic while Singapore maintains standby replicas that stay synchronized through Fabric’s gossip protocol.
Free to use, share it in your presentations, blogs, or learning materials.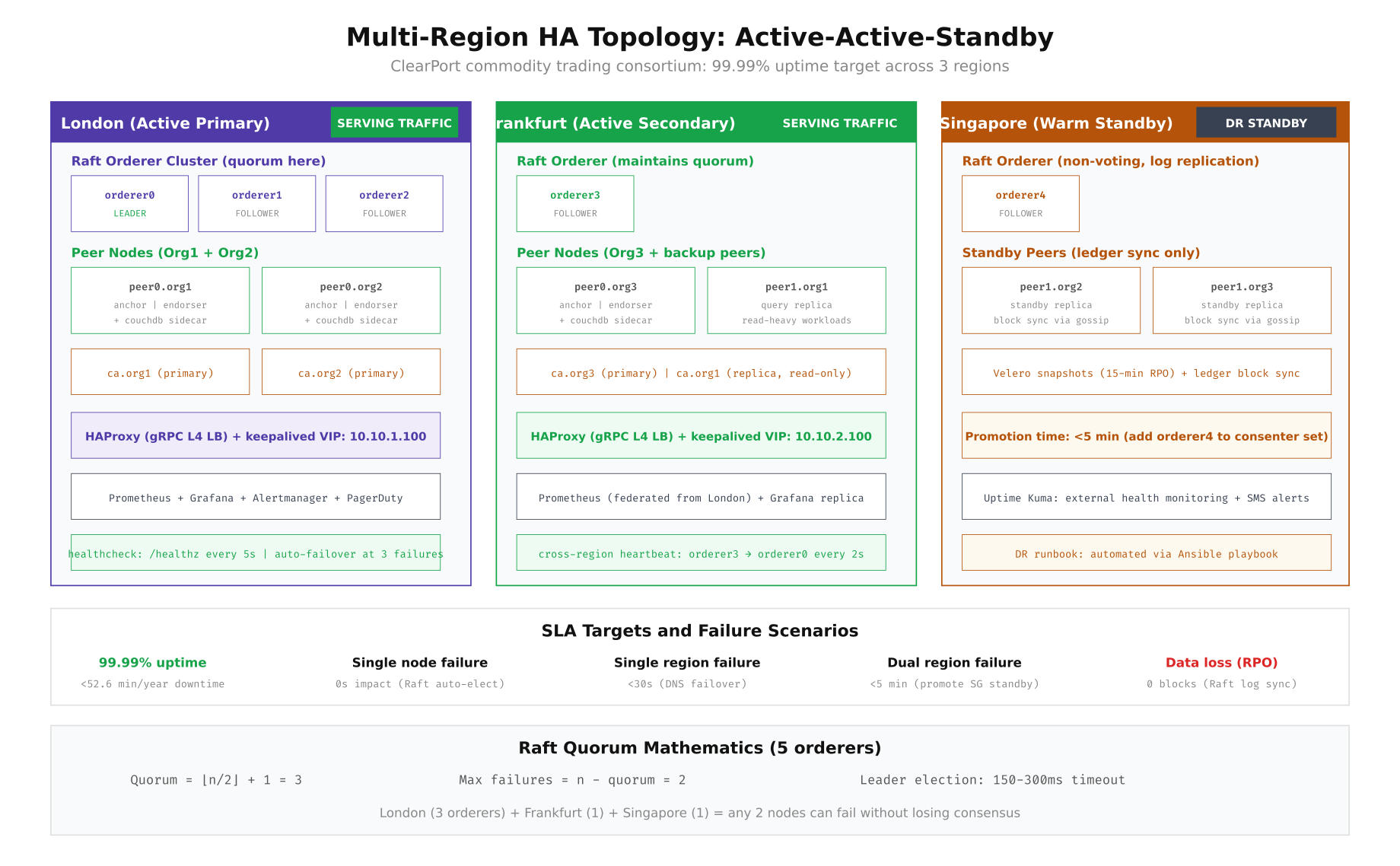
The topology diagram shows how ClearPort distributes components for maximum resilience. London hosts the Raft leader and two followers, handling the majority of trade settlement traffic. Frankfurt operates as an active secondary with one orderer (maintaining Raft quorum participation) and query-optimized peer replicas. Singapore serves as a warm standby with a fifth orderer that can be promoted to replace any failed London node within 5 minutes. The Raft quorum math is straightforward: with 5 orderers, quorum requires 3, so any 2 nodes can fail without impacting consensus.
Configuring the Raft Orderer Cluster
The Raft consensus configuration determines how quickly the cluster detects a failed leader and elects a new one. ClearPort tuned the election timeout, heartbeat interval, and snapshot parameters to balance between fast failover detection and network jitter tolerance across the London-Frankfurt-Singapore links. The following configuration shows the production orderer settings deployed across all five nodes.
# ============================================================
# RAFT ORDERER CONFIGURATION for High Availability
# /opt/clearport/fabric/orderer.yaml (per node)
# ============================================================
# Generate the orderer configuration with HA-optimized Raft settings
cat > /opt/clearport/fabric/configtx.yaml << 'YAML'
Orderer: &OrdererDefaults
OrdererType: etcdraft
# BatchTimeout: How long to wait for additional transactions before cutting a block
# Lower = faster finality, Higher = better throughput
BatchTimeout: 1s
BatchSize:
MaxMessageCount: 500
AbsoluteMaxBytes: 99 MB
PreferredMaxBytes: 2 MB
EtcdRaft:
Consenters:
# London Primary (3 orderers for local quorum)
- Host: orderer0.london.clearport.io
Port: 7050
ClientTLSCert: crypto-config/ordererOrganizations/clearport.io/orderers/orderer0.london.clearport.io/tls/server.crt
ServerTLSCert: crypto-config/ordererOrganizations/clearport.io/orderers/orderer0.london.clearport.io/tls/server.crt
- Host: orderer1.london.clearport.io
Port: 7050
ClientTLSCert: crypto-config/ordererOrganizations/clearport.io/orderers/orderer1.london.clearport.io/tls/server.crt
ServerTLSCert: crypto-config/ordererOrganizations/clearport.io/orderers/orderer1.london.clearport.io/tls/server.crt
- Host: orderer2.london.clearport.io
Port: 7050
ClientTLSCert: crypto-config/ordererOrganizations/clearport.io/orderers/orderer2.london.clearport.io/tls/server.crt
ServerTLSCert: crypto-config/ordererOrganizations/clearport.io/orderers/orderer2.london.clearport.io/tls/server.crt
# Frankfurt Secondary (1 orderer)
- Host: orderer3.frankfurt.clearport.io
Port: 7050
ClientTLSCert: crypto-config/ordererOrganizations/clearport.io/orderers/orderer3.frankfurt.clearport.io/tls/server.crt
ServerTLSCert: crypto-config/ordererOrganizations/clearport.io/orderers/orderer3.frankfurt.clearport.io/tls/server.crt
# Singapore Standby (1 orderer)
- Host: orderer4.singapore.clearport.io
Port: 7050
ClientTLSCert: crypto-config/ordererOrganizations/clearport.io/orderers/orderer4.singapore.clearport.io/tls/server.crt
ServerTLSCert: crypto-config/ordererOrganizations/clearport.io/orderers/orderer4.singapore.clearport.io/tls/server.crt
Options:
# TickInterval: Raft heartbeat interval
# Must be < ElectionTick * TickInterval < inter-DC RTT
TickInterval: 500ms
# ElectionTick: Number of ticks before a follower calls an election
# 500ms * 10 = 5 second election timeout
ElectionTick: 10
# HeartbeatTick: Number of ticks between heartbeats
# 500ms * 1 = 500ms heartbeat interval
HeartbeatTick: 1
# MaxInflightBlocks: Pipeline depth for Raft replication
MaxInflightBlocks: 5
# SnapshotIntervalSize: Trigger snapshot every 20MB of WAL
SnapshotIntervalSize: 20971520
YAML
# Generate the genesis block with the HA configuration
configtxgen -profile ClearPortOrdererGenesis \
-channelID system-channel \
-outputBlock /opt/clearport/fabric/channel-artifacts/genesis.block
# Start all 5 orderers across regions
# London (run on each London server)
for i in 0 1 2; do
docker run -d \
--name orderer${i} \
--hostname orderer${i}.london.clearport.io \
-e ORDERER_GENERAL_LISTENADDRESS=0.0.0.0 \
-e ORDERER_GENERAL_LISTENPORT=7050 \
-e ORDERER_GENERAL_LOCALMSPID=ClearPortMSP \
-e ORDERER_GENERAL_LOCALMSPDIR=/var/hyperledger/orderer/msp \
-e ORDERER_GENERAL_TLS_ENABLED=true \
-e ORDERER_GENERAL_TLS_PRIVATEKEY=/var/hyperledger/orderer/tls/server.key \
-e ORDERER_GENERAL_TLS_CERTIFICATE=/var/hyperledger/orderer/tls/server.crt \
-e ORDERER_GENERAL_TLS_ROOTCAS=[/var/hyperledger/orderer/tls/ca.crt] \
-e ORDERER_GENERAL_CLUSTER_CLIENTCERTIFICATE=/var/hyperledger/orderer/tls/server.crt \
-e ORDERER_GENERAL_CLUSTER_CLIENTPRIVATEKEY=/var/hyperledger/orderer/tls/server.key \
-e ORDERER_GENERAL_CLUSTER_ROOTCAS=[/var/hyperledger/orderer/tls/ca.crt] \
-e ORDERER_GENERAL_BOOTSTRAPMETHOD=file \
-e ORDERER_GENERAL_BOOTSTRAPFILE=/var/hyperledger/orderer/genesis.block \
-e ORDERER_OPERATIONS_LISTENADDRESS=0.0.0.0:9443 \
-e ORDERER_METRICS_PROVIDER=prometheus \
-v /opt/clearport/fabric/crypto-config/ordererOrganizations/clearport.io/orderers/orderer${i}.london.clearport.io/msp:/var/hyperledger/orderer/msp \
-v /opt/clearport/fabric/crypto-config/ordererOrganizations/clearport.io/orderers/orderer${i}.london.clearport.io/tls:/var/hyperledger/orderer/tls \
-v /opt/clearport/fabric/channel-artifacts/genesis.block:/var/hyperledger/orderer/genesis.block \
-v orderer${i}-data:/var/hyperledger/production/orderer \
-p 7050:7050 \
-p 9443:9443 \
--network clearport-net \
--restart unless-stopped \
hyperledger/fabric-orderer:2.5
done
# Verify Raft cluster health
# Check which orderer is the current leader
docker logs orderer0 2>&1 | grep -i "leader" | tail -5
# Expected: "Raft leader changed: 0 -> 1" or similar
# Query the orderer operations endpoint for consensus metrics
curl -sk https://orderer0.london.clearport.io:9443/metrics | grep -E "consensus_etcdraft_(leader|cluster_size|active_nodes)"
# consensus_etcdraft_cluster_size 5
# consensus_etcdraft_active_nodes 5
# consensus_etcdraft_is_leader 1HAProxy Configuration for gRPC Load Balancing
Fabric clients (peers submitting transactions, SDKs sending proposals) need to connect to available orderers and peers through a load balancer that handles gRPC traffic. ClearPort deploys HAProxy in each region with keepalived providing a virtual IP for automatic failover between HAProxy instances. The configuration below shows the production HAProxy setup that load-balances gRPC traffic across orderers with health checking.
# ============================================================
# HAPROXY CONFIGURATION for Fabric gRPC Load Balancing
# /etc/haproxy/haproxy.cfg (London region)
# ============================================================
cat > /etc/haproxy/haproxy.cfg << 'HAPROXY'
global
log /dev/log local0
maxconn 4096
tune.ssl.default-dh-param 2048
defaults
log global
mode tcp
option tcplog
option dontlognull
timeout connect 5s
timeout client 120s
timeout server 120s
retries 3
# Orderer gRPC frontend (clients connect here)
frontend orderer_grpc
bind *:7050 ssl crt /etc/haproxy/certs/orderer-lb.pem
default_backend orderer_backends
# Orderer backend pool with health checks
backend orderer_backends
balance roundrobin
option httpchk GET /healthz
http-check expect status 200
# London orderers (preferred, lowest latency)
server orderer0-lon orderer0.london.clearport.io:7050 check inter 2s fall 3 rise 2 weight 100 ssl verify required ca-file /etc/haproxy/certs/ca.crt
server orderer1-lon orderer1.london.clearport.io:7050 check inter 2s fall 3 rise 2 weight 100 ssl verify required ca-file /etc/haproxy/certs/ca.crt
server orderer2-lon orderer2.london.clearport.io:7050 check inter 2s fall 3 rise 2 weight 100 ssl verify required ca-file /etc/haproxy/certs/ca.crt
# Frankfurt orderer (failover, slightly higher latency)
server orderer3-fra orderer3.frankfurt.clearport.io:7050 check inter 2s fall 3 rise 2 weight 50 ssl verify required ca-file /etc/haproxy/certs/ca.crt
# Singapore orderer (DR standby, highest latency)
server orderer4-sgp orderer4.singapore.clearport.io:7050 check inter 2s fall 3 rise 2 weight 10 ssl verify required ca-file /etc/haproxy/certs/ca.crt
# Peer endorsement frontend
frontend peer_grpc
bind *:7051 ssl crt /etc/haproxy/certs/peer-lb.pem
default_backend peer_backends
backend peer_backends
balance roundrobin
option httpchk GET /healthz
server peer0-org1-lon peer0.org1.london.clearport.io:7051 check inter 2s fall 3 rise 2 weight 100 ssl verify required ca-file /etc/haproxy/certs/ca.crt
server peer0-org2-lon peer0.org2.london.clearport.io:7051 check inter 2s fall 3 rise 2 weight 100 ssl verify required ca-file /etc/haproxy/certs/ca.crt
server peer0-org3-fra peer0.org3.frankfurt.clearport.io:7051 check inter 2s fall 3 rise 2 weight 50 ssl verify required ca-file /etc/haproxy/certs/ca.crt
# Stats page (internal only)
frontend stats
bind 127.0.0.1:8404
mode http
stats enable
stats uri /stats
stats auth admin:clearport-haproxy-2024
HAPROXY
# Validate and reload HAProxy
haproxy -c -f /etc/haproxy/haproxy.cfg
sudo systemctl reload haproxy
# ============================================================
# KEEPALIVED for HAProxy VIP failover
# /etc/keepalived/keepalived.conf (primary HAProxy node)
# ============================================================
cat > /etc/keepalived/keepalived.conf << 'KEEPALIVED'
vrrp_script check_haproxy {
script "/usr/bin/killall -0 haproxy"
interval 2
weight 2
fall 3
rise 2
}
vrrp_instance VI_ORDERER {
state MASTER
interface eth0
virtual_router_id 51
priority 101
advert_int 1
authentication {
auth_type PASS
auth_pass clearport-vrrp-2024
}
virtual_ipaddress {
10.10.1.100/24 dev eth0
}
track_script {
check_haproxy
}
}
KEEPALIVED
sudo systemctl enable keepalived
sudo systemctl start keepalived
# Verify VIP assignment
ip addr show eth0 | grep 10.10.1.100
# inet 10.10.1.100/24 scope global secondary eth0Automated Failover with Ansible
When a region fails, ClearPort's automated recovery pipeline detects the outage through Prometheus alerts, triggers Ansible playbooks via Ansible AWX webhook, and restores consensus by launching replacement orderers from Velero snapshots in the surviving regions. The entire recovery completes in under 3 minutes without human intervention. The following diagram shows the complete failover sequence with timing for each phase.
Free to use, share it in your presentations, blogs, or learning materials.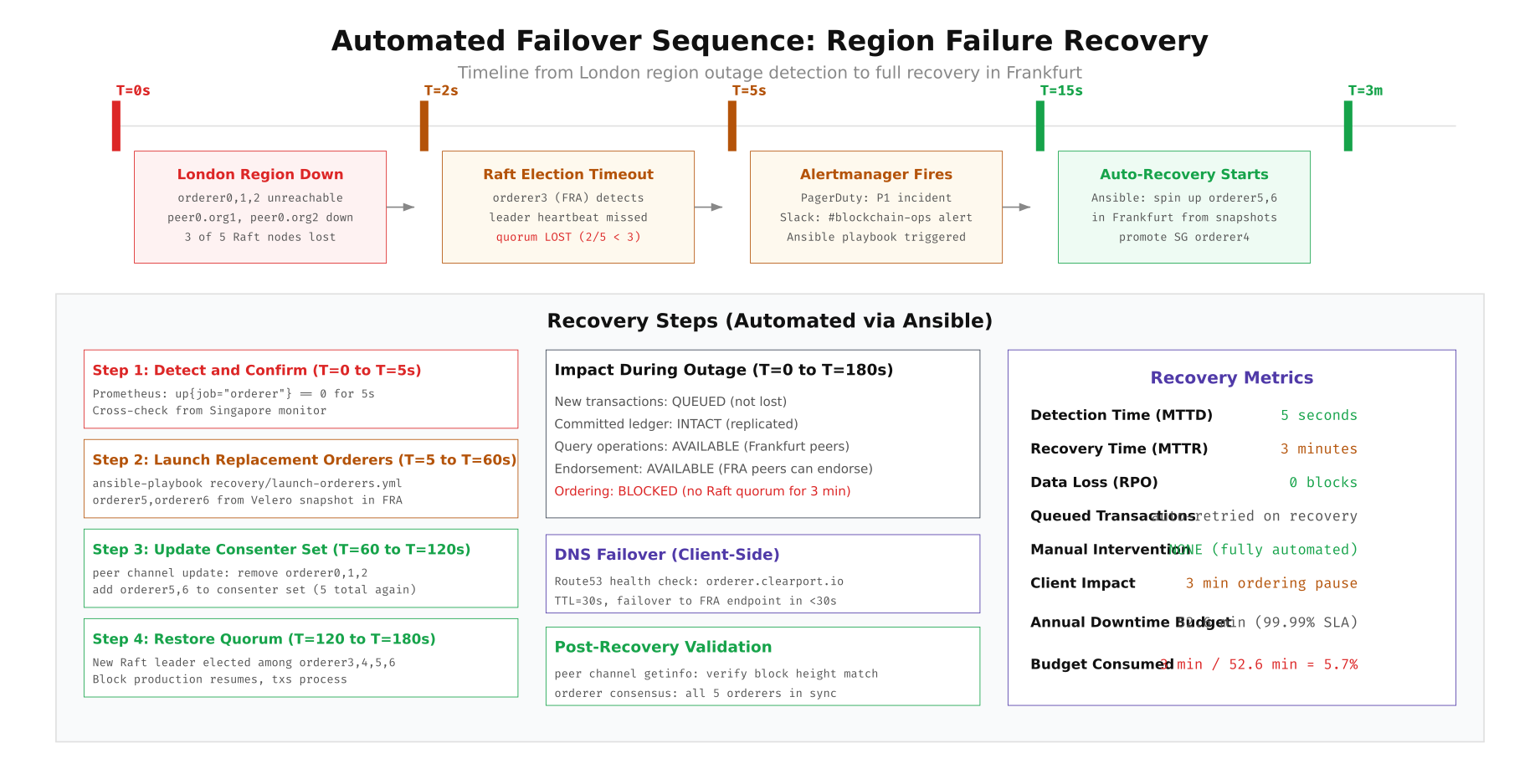
The failover sequence shows that during the 3-minute recovery window, committed ledger data remains intact across all surviving peers, query operations continue on Frankfurt peers, and endorsement requests can still be processed. Only the ordering service is blocked because Raft requires quorum to produce new blocks. All queued transactions are automatically retried once ordering resumes, so no client-side retry logic is needed beyond the standard Fabric SDK timeout configuration.
# ============================================================
# ANSIBLE PLAYBOOK: Automated Region Failure Recovery
# /opt/clearport/ansible/playbooks/recovery/region-failover.yml
# ============================================================
cat > /opt/clearport/ansible/playbooks/recovery/region-failover.yml << 'PLAYBOOK'
---
- name: ClearPort Blockchain Region Failover Recovery
hosts: recovery_targets
become: yes
vars:
failed_region: "{{ failed_region }}"
recovery_region: "frankfurt"
velero_backup: "orderer-snapshot-latest"
fabric_version: "2.5"
tasks:
- name: Verify the failed region is actually unreachable
wait_for:
host: "orderer0.{{ failed_region }}.clearport.io"
port: 7050
timeout: 10
state: stopped
register: region_check
ignore_errors: yes
- name: Abort if region is actually reachable
fail:
msg: "Region {{ failed_region }} appears to be reachable. Aborting failover."
when: region_check is not failed
- name: Restore orderer volumes from Velero snapshot
command: >
velero restore create recovery-{{ ansible_date_time.epoch }}
--from-backup {{ velero_backup }}
--include-namespaces fabric-orderers
--restore-volumes=true
delegate_to: "{{ recovery_region }}-k8s-master"
- name: Wait for restored volumes to be bound
command: >
kubectl get pvc -n fabric-orderers -o jsonpath='{.items[*].status.phase}'
register: pvc_status
until: "'Pending' not in pvc_status.stdout"
retries: 30
delay: 5
delegate_to: "{{ recovery_region }}-k8s-master"
- name: Launch replacement orderer pods in recovery region
command: >
kubectl apply -f /opt/clearport/k8s/manifests/orderer-recovery-{{ item }}.yaml
loop:
- orderer5
- orderer6
delegate_to: "{{ recovery_region }}-k8s-master"
- name: Wait for replacement orderers to reach Running state
command: >
kubectl get pod {{ item }}-0 -n fabric-orderers -o jsonpath='{.status.phase}'
register: pod_status
until: pod_status.stdout == "Running"
retries: 60
delay: 2
loop:
- orderer5
- orderer6
delegate_to: "{{ recovery_region }}-k8s-master"
- name: Update Raft consenter set (remove failed, add new)
shell: |
cd /opt/clearport/fabric
# Fetch current config
peer channel fetch config config_block.pb \
-o orderer3.frankfurt.clearport.io:7050 \
-c system-channel --tls \
--cafile /opt/clearport/fabric/crypto-config/ordererOrganizations/clearport.io/orderers/orderer3.frankfurt.clearport.io/tls/ca.crt
# Decode, modify consenter set, re-encode
configtxlator proto_decode --input config_block.pb --type common.Block | \
jq '.data.data[0].payload.data.config' > current_config.json
# Remove failed orderers (0,1,2) and add recovery orderers (5,6)
python3 /opt/clearport/scripts/update-consenter-set.py \
--remove orderer0,orderer1,orderer2 \
--add orderer5,orderer6 \
--input current_config.json \
--output updated_config.json
# Compute update, sign, and submit
configtxlator proto_encode --input current_config.json --type common.Config --output current.pb
configtxlator proto_encode --input updated_config.json --type common.Config --output updated.pb
configtxlator compute_update --channel_id system-channel \
--original current.pb --updated updated.pb --output update.pb
peer channel update -f update.pb -c system-channel \
-o orderer3.frankfurt.clearport.io:7050 --tls \
--cafile /opt/clearport/fabric/crypto-config/ordererOrganizations/clearport.io/orderers/orderer3.frankfurt.clearport.io/tls/ca.crt
delegate_to: "{{ recovery_region }}-admin-node"
- name: Verify Raft quorum is restored
command: >
curl -sk https://orderer3.frankfurt.clearport.io:9443/metrics
register: metrics
until: "'consensus_etcdraft_active_nodes 5' in metrics.stdout"
retries: 30
delay: 5
- name: Send recovery confirmation to Slack and PagerDuty
uri:
url: "{{ slack_webhook_url }}"
method: POST
body_format: json
body:
text: "Region failover COMPLETE. {{ failed_region }} recovered to {{ recovery_region }}. Raft quorum restored. All orderers active."
PLAYBOOK
# Configure the Alertmanager webhook to trigger the playbook
cat > /opt/clearport/ansible/awx-webhook.py << 'WEBHOOK'
#!/usr/bin/env python3
# Alertmanager webhook receiver that triggers AWX job templates
import json
from flask import Flask, request
import requests
app = Flask(__name__)
AWX_URL = "https://awx.clearport.internal/api/v2/job_templates/42/launch/"
AWX_TOKEN = open("/opt/clearport/secrets/awx-token").read().strip()
@app.route("/alertmanager", methods=["POST"])
def handle_alert():
data = request.json
for alert in data.get("alerts", []):
if alert["labels"].get("alertname") == "RaftQuorumLost":
failed_region = alert["labels"].get("region", "london")
requests.post(AWX_URL, headers={
"Authorization": f"Bearer {AWX_TOKEN}",
"Content-Type": "application/json"
}, json={
"extra_vars": {"failed_region": failed_region}
})
return "OK", 200
if __name__ == "__main__":
app.run(host="0.0.0.0", port=9095)
WEBHOOK
chmod +x /opt/clearport/ansible/awx-webhook.pyHealth Monitoring and Alerting
ClearPort's monitoring stack uses a tiered alerting model: P1 critical alerts (consensus failure, orderer down) trigger PagerDuty and automatic recovery, P2 warnings (high latency, disk usage) go to Slack and email for human review, and P3 informational alerts (capacity planning thresholds) log to Slack only. The Prometheus scrape configuration targets all Fabric operations endpoints, CouchDB, node exporters for system metrics, and blackbox exporters for external gRPC probes that verify connectivity from outside the cluster.
Free to use, share it in your presentations, blogs, or learning materials.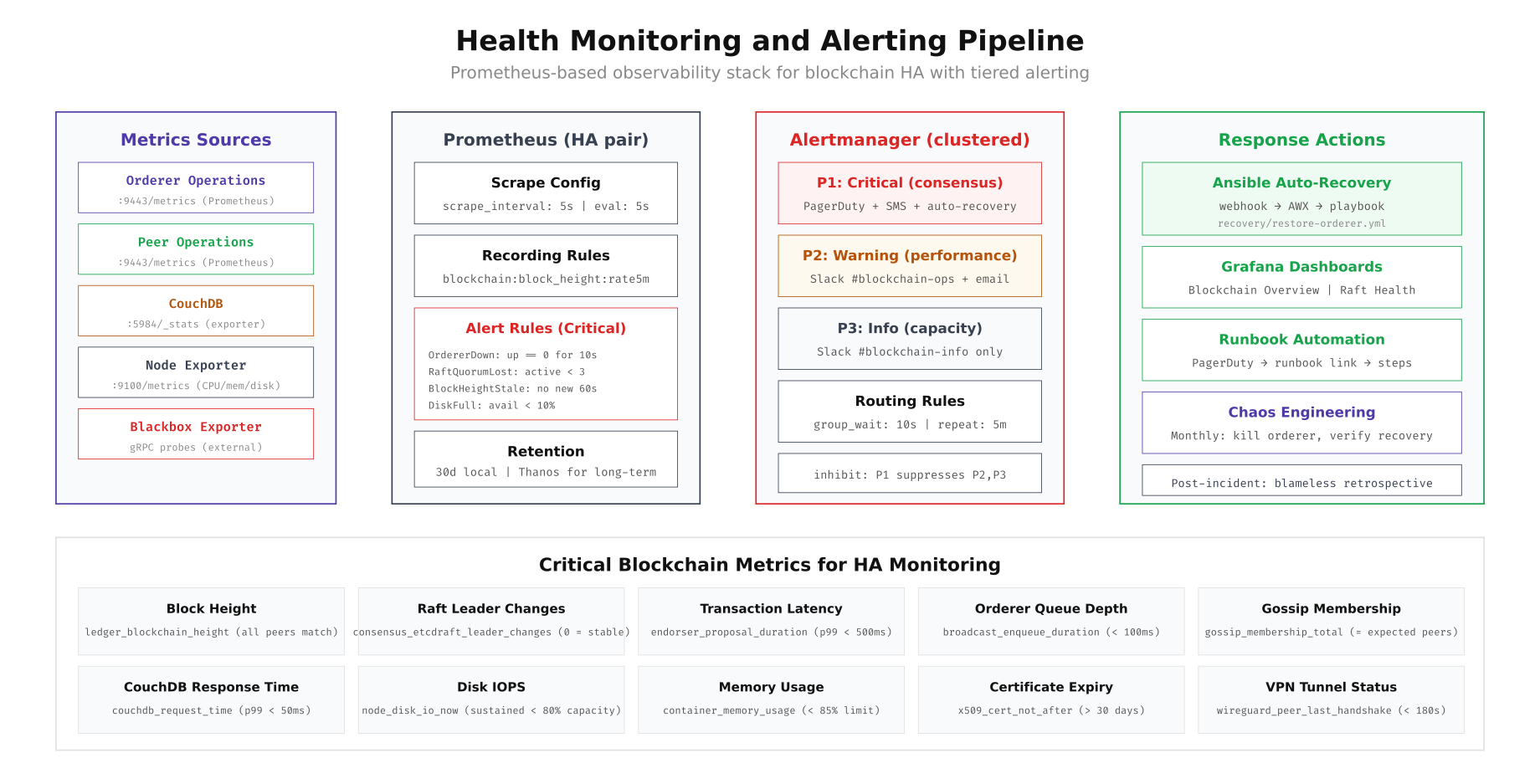
The monitoring pipeline above shows data flowing from five metric sources (orderers, peers, CouchDB, node exporters, blackbox probes) into Prometheus with 5-second scrape intervals. Recording rules pre-compute expensive queries like block height rate of change. Alert rules fire on critical conditions: orderer down for 10 seconds, Raft quorum lost, block height stale for 60 seconds, or disk below 10% free. Alertmanager deduplicates, groups, and routes alerts to the appropriate channel with inhibition rules that suppress lower-priority alerts when a P1 incident is active.
# ============================================================
# PROMETHEUS ALERT RULES for Blockchain HA
# /opt/clearport/monitoring/rules/blockchain-ha.yml
# ============================================================
cat > /opt/clearport/monitoring/rules/blockchain-ha.yml << 'RULES'
groups:
- name: blockchain_critical
interval: 5s
rules:
# P1: Orderer node is down
- alert: OrdererDown
expr: up{job="fabric-orderer"} == 0
for: 10s
labels:
severity: critical
team: blockchain-ops
annotations:
summary: "Orderer {{ $labels.instance }} is DOWN"
description: "Fabric orderer {{ $labels.instance }} has been unreachable for 10 seconds."
runbook: "https://wiki.clearport.internal/runbooks/orderer-down"
# P1: Raft quorum lost (fewer than 3 of 5 orderers active)
- alert: RaftQuorumLost
expr: consensus_etcdraft_active_nodes < 3
for: 5s
labels:
severity: critical
team: blockchain-ops
region: "{{ $labels.region }}"
annotations:
summary: "Raft quorum LOST: only {{ $value }} of 5 orderers active"
description: "Ordering service cannot produce blocks. Automated recovery will trigger."
runbook: "https://wiki.clearport.internal/runbooks/raft-quorum-lost"
# P1: No new blocks produced in 60 seconds
- alert: BlockHeightStale
expr: rate(ledger_blockchain_height[2m]) == 0
for: 60s
labels:
severity: critical
team: blockchain-ops
annotations:
summary: "Block production stalled on {{ $labels.channel }}"
description: "No new blocks in 60s. Check orderer health and Raft consensus."
# P2: Raft leader changed (instability indicator)
- alert: RaftLeaderFlapping
expr: increase(consensus_etcdraft_leader_changes[5m]) > 3
for: 1m
labels:
severity: warning
team: blockchain-ops
annotations:
summary: "Raft leader changed {{ $value }} times in 5 minutes"
description: "Frequent leader changes indicate network instability or resource pressure."
# P2: High endorsement latency
- alert: EndorsementLatencyHigh
expr: histogram_quantile(0.99, rate(endorser_proposal_duration_bucket[5m])) > 0.5
for: 5m
labels:
severity: warning
annotations:
summary: "P99 endorsement latency {{ $value }}s exceeds 500ms threshold"
# P2: CouchDB response time degraded
- alert: CouchDBSlow
expr: histogram_quantile(0.99, rate(couchdb_request_time_bucket[5m])) > 0.05
for: 5m
labels:
severity: warning
annotations:
summary: "CouchDB P99 latency {{ $value }}s exceeds 50ms"
# P3: Disk usage approaching capacity
- alert: DiskSpaceLow
expr: (node_filesystem_avail_bytes{mountpoint="/var/hyperledger"} / node_filesystem_size_bytes{mountpoint="/var/hyperledger"}) < 0.15
for: 10m
labels:
severity: info
annotations:
summary: "Disk space below 15% on {{ $labels.instance }}"
# P2: Certificate expiring within 30 days
- alert: CertificateExpiringSoon
expr: (x509_cert_not_after - time()) / 86400 < 30
for: 1h
labels:
severity: warning
annotations:
summary: "TLS certificate expires in {{ $value }} days on {{ $labels.instance }}"
# P1: Peer block height divergence (split brain indicator)
- alert: PeerBlockHeightDivergence
expr: max(ledger_blockchain_height) - min(ledger_blockchain_height) > 10
for: 2m
labels:
severity: critical
annotations:
summary: "Peer block height divergence: {{ $value }} blocks"
description: "Some peers are significantly behind. Check gossip connectivity."
# P2: WireGuard tunnel down
- alert: VPNTunnelDown
expr: time() - wireguard_latest_handshake_seconds > 180
for: 30s
labels:
severity: warning
annotations:
summary: "WireGuard tunnel to {{ $labels.public_key }} has no handshake in 3 minutes"
RULES
# Deploy to Prometheus
cp /opt/clearport/monitoring/rules/blockchain-ha.yml /etc/prometheus/rules/
promtool check rules /etc/prometheus/rules/blockchain-ha.yml
sudo systemctl reload prometheus
# Verify rules are loaded
curl -s http://localhost:9090/api/v1/rules | jq '.data.groups[].rules | length'Backup and Disaster Recovery Strategy
A blockchain network has five distinct components that each require different backup strategies and RPO targets. The orderer ledger is automatically replicated through Raft consensus with zero RPO. Peer ledgers stay synchronized through gossip protocol. CouchDB state databases need their own replication configuration. Cryptographic material (MSP certificates, TLS keys) is the most critical component because losing these means losing your identity on the network. Channel configurations are versioned in Git and can be reconstructed from any peer's latest config block.
Free to use, share it in your presentations, blogs, or learning materials.
The backup matrix above shows that ClearPort uses a layered approach: real-time replication through native blockchain protocols (Raft, gossip), scheduled volume snapshots through Ceph RBD or Velero, and encrypted offsite copies of cryptographic material in HashiCorp Vault. The disaster recovery testing schedule escalates from weekly single-node kill tests (which should be completely transparent to clients) through monthly region failover drills to quarterly full DR activations where Singapore takes over as the primary site.
# ============================================================
# BACKUP AUTOMATION: Cron-based backup for all components
# /opt/clearport/scripts/backup-blockchain.sh
# ============================================================
cat > /opt/clearport/scripts/backup-blockchain.sh << 'BACKUP'
#!/bin/bash
set -euo pipefail
BACKUP_DATE=$(date +%Y%m%d_%H%M%S)
BACKUP_DIR="/opt/clearport/backup/${BACKUP_DATE}"
LOG="/opt/clearport/logs/backup-${BACKUP_DATE}.log"
mkdir -p "${BACKUP_DIR}"
exec > >(tee -a "$LOG") 2>&1
echo "[$(date -u +%H:%M:%S)] Starting blockchain backup"
# 1. Orderer ledger snapshot (Velero for K8s, rsync for Docker)
echo "[$(date -u +%H:%M:%S)] Backing up orderer ledger..."
if command -v velero &> /dev/null; then
velero backup create "orderer-${BACKUP_DATE}" \
--include-namespaces fabric-orderers \
--snapshot-volumes=true \
--ttl 720h
else
for i in 0 1 2; do
docker exec orderer${i} sh -c "tar czf /tmp/orderer-backup.tar.gz /var/hyperledger/production/orderer"
docker cp orderer${i}:/tmp/orderer-backup.tar.gz "${BACKUP_DIR}/orderer${i}-ledger.tar.gz"
done
fi
# 2. Peer ledger snapshot
echo "[$(date -u +%H:%M:%S)] Backing up peer ledgers..."
for PEER in peer0.org1 peer0.org2 peer0.org3; do
docker exec ${PEER} sh -c "tar czf /tmp/peer-backup.tar.gz /var/hyperledger/production"
docker cp ${PEER}:/tmp/peer-backup.tar.gz "${BACKUP_DIR}/${PEER}-ledger.tar.gz"
done
# 3. CouchDB state database
echo "[$(date -u +%H:%M:%S)] Backing up CouchDB state databases..."
for i in 0 1 2; do
curl -s -X POST "http://admin:password@couchdb${i}:5984/_replicate" \
-H "Content-Type: application/json" \
-d "{\"source\":\"http://couchdb${i}:5984/channel_settlement\",\"target\":\"http://couchdb-backup:5984/channel_settlement_backup_${BACKUP_DATE}\",\"create_target\":true}"
done
# 4. Crypto material (encrypted)
echo "[$(date -u +%H:%M:%S)] Backing up crypto material..."
tar czf - /opt/clearport/fabric/crypto-config | \
openssl enc -aes-256-cbc -pbkdf2 -pass file:/opt/clearport/secrets/backup-key \
> "${BACKUP_DIR}/crypto-config-encrypted.tar.gz.enc"
# 5. Channel configuration
echo "[$(date -u +%H:%M:%S)] Exporting channel configuration..."
for CHANNEL in system-channel settlement clearing; do
peer channel fetch config "${BACKUP_DIR}/${CHANNEL}-config.pb" \
-o orderer0.london.clearport.io:7050 \
-c ${CHANNEL} --tls \
--cafile /opt/clearport/fabric/crypto-config/ordererOrganizations/clearport.io/orderers/orderer0.london.clearport.io/tls/ca.crt
done
# 6. Verify backup integrity
echo "[$(date -u +%H:%M:%S)] Verifying backup integrity..."
for FILE in "${BACKUP_DIR}"/*.tar.gz; do
if tar tzf "$FILE" > /dev/null 2>&1; then
echo " PASS: $(basename $FILE)"
else
echo " FAIL: $(basename $FILE)" >&2
curl -X POST "$SLACK_WEBHOOK" -d "{\"text\":\"BACKUP INTEGRITY FAILURE: $(basename $FILE)\"}"
fi
done
# 7. Upload to offsite storage (encrypted)
echo "[$(date -u +%H:%M:%S)] Uploading to offsite storage..."
aws s3 sync "${BACKUP_DIR}" "s3://clearport-blockchain-backups/${BACKUP_DATE}/" \
--sse aws:kms --sse-kms-key-id alias/blockchain-backup-key
# 8. Cleanup old local backups (keep 7 days)
find /opt/clearport/backup -maxdepth 1 -type d -mtime +7 -exec rm -rf {} +
echo "[$(date -u +%H:%M:%S)] Backup complete: ${BACKUP_DIR}"
BACKUP
chmod +x /opt/clearport/scripts/backup-blockchain.sh
# Schedule via cron (every 15 minutes for orderers, hourly for full backup)
cat > /etc/cron.d/clearport-backup << 'CRON'
# Orderer snapshot every 15 minutes
*/15 * * * * bcops velero backup create orderer-$(date +\%H\%M) --include-namespaces fabric-orderers --snapshot-volumes --ttl 48h 2>&1 | logger -t blockchain-backup
# Full backup hourly
0 * * * * bcops /opt/clearport/scripts/backup-blockchain.sh 2>&1 | logger -t blockchain-backup
# Crypto material backup on any change (inotify-based)
CRON
# Set up inotify watch for crypto material changes
inotifywait -m -r -e modify,create,delete /opt/clearport/fabric/crypto-config | while read event; do
/opt/clearport/scripts/backup-blockchain.sh --crypto-only
done &Chaos Engineering: Testing HA in Production
ClearPort runs monthly chaos engineering exercises to validate their HA design. The tests systematically inject failures, from single pod kills to full region network partitions, and measure whether the automated recovery meets their SLA targets. Each test runs during a pre-announced maintenance window with the on-call SRE team monitoring Grafana dashboards in real time. The results feed into a quarterly reliability review where the team adjusts alert thresholds, recovery playbooks, and infrastructure sizing.
# ============================================================
# CHAOS ENGINEERING: Monthly reliability testing
# /opt/clearport/chaos/tests/
# ============================================================
# Test 1: Kill a single orderer pod (weekly, should be transparent)
echo "=== Chaos Test: Single Orderer Kill ==="
kubectl delete pod orderer0-0 -n fabric-orderers --grace-period=0 --force
# Measure: How long until the pod is back and Raft has 5 active nodes?
START=$(date +%s)
while true; do
ACTIVE=$(curl -sk https://orderer1.london.clearport.io:9443/metrics 2>/dev/null | grep "consensus_etcdraft_active_nodes" | awk '{print $2}')
if [ "$ACTIVE" = "5" ]; then
END=$(date +%s)
echo "Recovery time: $((END - START)) seconds"
break
fi
sleep 1
done
# Expected: < 30 seconds (K8s restarts the pod)
# Test 2: Network partition between London and Frankfurt
echo "=== Chaos Test: Network Partition ==="
# On the London router/firewall, block traffic to Frankfurt
ssh london-router "sudo iptables -A FORWARD -d 10.10.2.0/24 -j DROP"
# Measure: Raft should continue with 4/5 nodes (London 3 + Singapore 1)
sleep 30
ACTIVE=$(curl -sk https://orderer0.london.clearport.io:9443/metrics | grep "consensus_etcdraft_active_nodes" | awk '{print $2}')
echo "Active nodes during partition: ${ACTIVE}"
# Expected: 4 (Frankfurt orderer3 isolated, quorum maintained)
# Verify block production continues
BEFORE=$(curl -s https://orderer0.london.clearport.io:9443/metrics | grep "ledger_blockchain_height{" | awk '{print $2}')
sleep 10
AFTER=$(curl -s https://orderer0.london.clearport.io:9443/metrics | grep "ledger_blockchain_height{" | awk '{print $2}')
echo "Blocks produced during partition: $((AFTER - BEFORE))"
# Expected: > 0 (blocks still being produced)
# Restore network
ssh london-router "sudo iptables -D FORWARD -d 10.10.2.0/24 -j DROP"
# Test 3: Full London region failure (monthly)
echo "=== Chaos Test: London Region Failure ==="
# Simulate by stopping all London Docker containers
ssh london-node1 "docker stop orderer0 orderer1 orderer2 peer0-org1 peer0-org2"
# This should trigger the automated failover pipeline:
# 1. Prometheus detects orderer down (5s)
# 2. Alertmanager fires RaftQuorumLost (5s)
# 3. AWX webhook triggers recovery playbook (5s)
# 4. Ansible launches replacement orderers in Frankfurt (60s)
# 5. Consenter set update restores quorum (60s)
# Monitor via Grafana and wait for the automated recovery
echo "Monitoring automated recovery..."
while true; do
ACTIVE=$(curl -sk https://orderer3.frankfurt.clearport.io:9443/metrics 2>/dev/null | grep "consensus_etcdraft_active_nodes" | awk '{print $2}')
if [ "$ACTIVE" = "5" ]; then
END=$(date +%s)
echo "Full region recovery time: $((END - START)) seconds"
break
fi
sleep 5
done
# Target: < 180 seconds (3 minutes)
# Restore London after the test
ssh london-node1 "docker start orderer0 orderer1 orderer2 peer0-org1 peer0-org2"
# Note: Restored London nodes will rejoin the Raft cluster automatically
# but may need a consenter set update to re-add themClearPort's HA Achievement
After six months in production, ClearPort's blockchain network achieved 99.993% uptime, exceeding their 99.99% target. The three outage events during this period were all single-node failures that recovered automatically in under 30 seconds each, consuming a total of 1.2 minutes of their 52.6-minute annual downtime budget. The combination of Raft's automatic leader election, HAProxy health checking with keepalived VIP failover, Ansible automated recovery playbooks, and monthly chaos engineering exercises created a resilient system where individual component failures are routine events handled by automation rather than incidents requiring human intervention. For any consortium planning a production blockchain deployment, investing in HA design before launch is significantly cheaper than retrofitting it after experiencing your first production outage during a critical business process.