
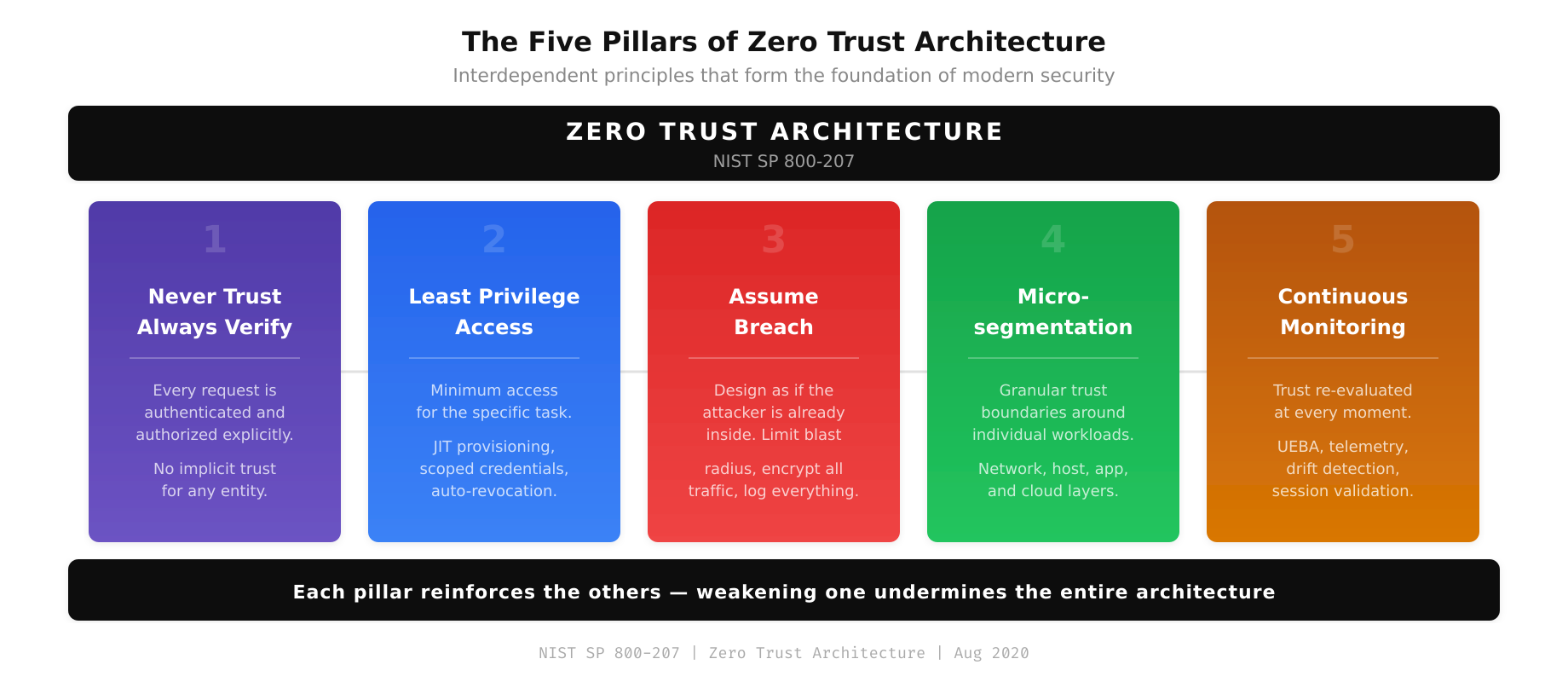
The Pillars That Define Zero Trust
Zero Trust Architecture (ZTA) is built on a set of core principles that, when implemented together, fundamentally change how an organization handles access, authentication, and authorization. These principles are not theoretical abstractions. They are engineering requirements that translate directly into infrastructure decisions, policy configurations, and operational procedures.
The National Institute of Standards and Technology (NIST) codified these principles in Special Publication 800-207, published in August 2020. While vendor interpretations vary, the underlying principles remain consistent. This post examines each core principle in technical depth and explores what implementation looks like in real production environments.
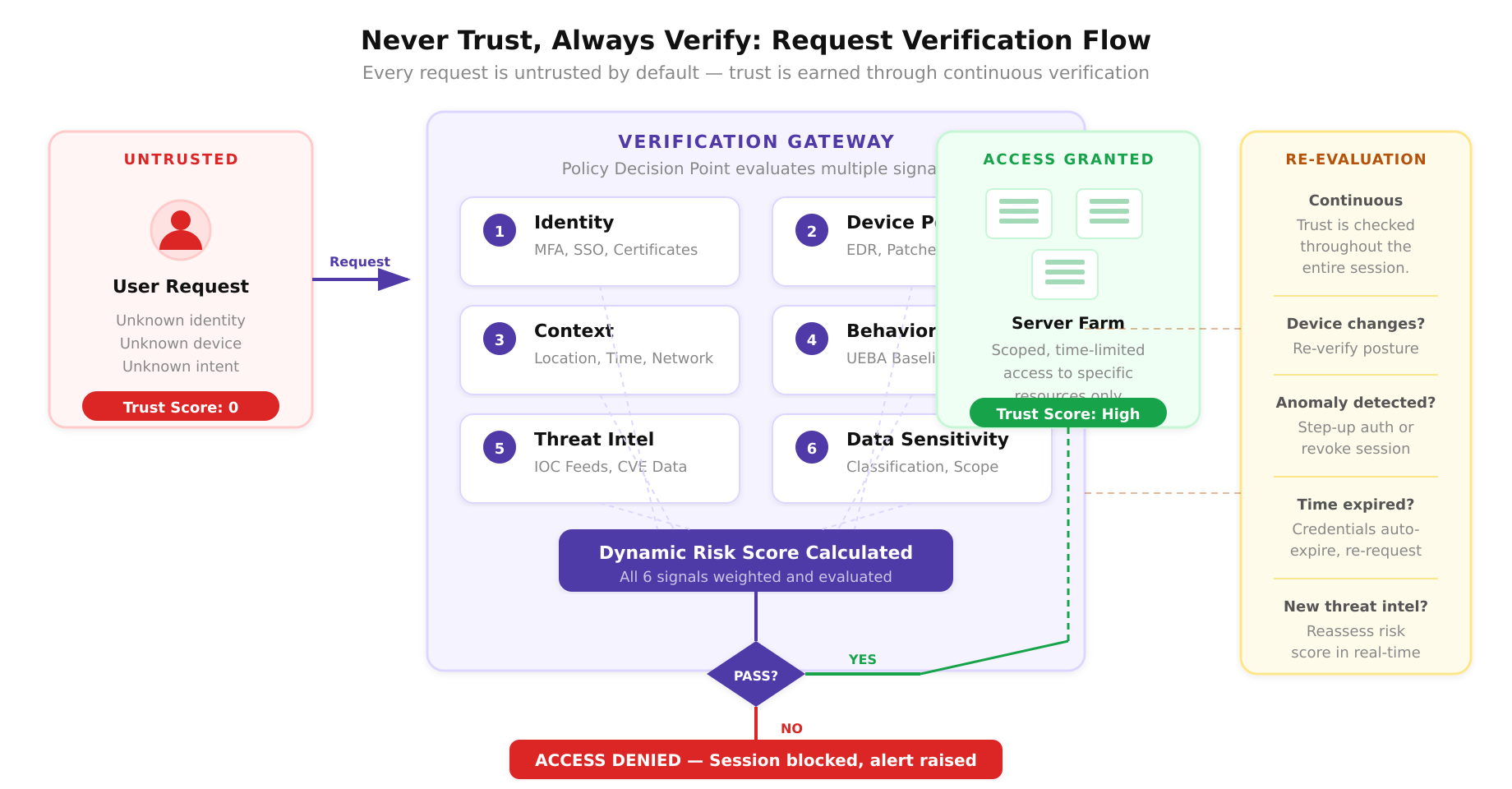
Principle 1: Never Trust, Always Verify
The foundational principle of Zero Trust is the elimination of implicit trust. In traditional architectures, a device on the corporate LAN is trusted. A user who has authenticated to the VPN is trusted. A service running in the production subnet is trusted. Zero Trust rejects all of these assumptions.
Every access request, regardless of source, must be explicitly verified. This verification is not a one-time event at session initiation. It is continuous. The policy engine re-evaluates trust throughout the lifetime of a connection based on changing signals.
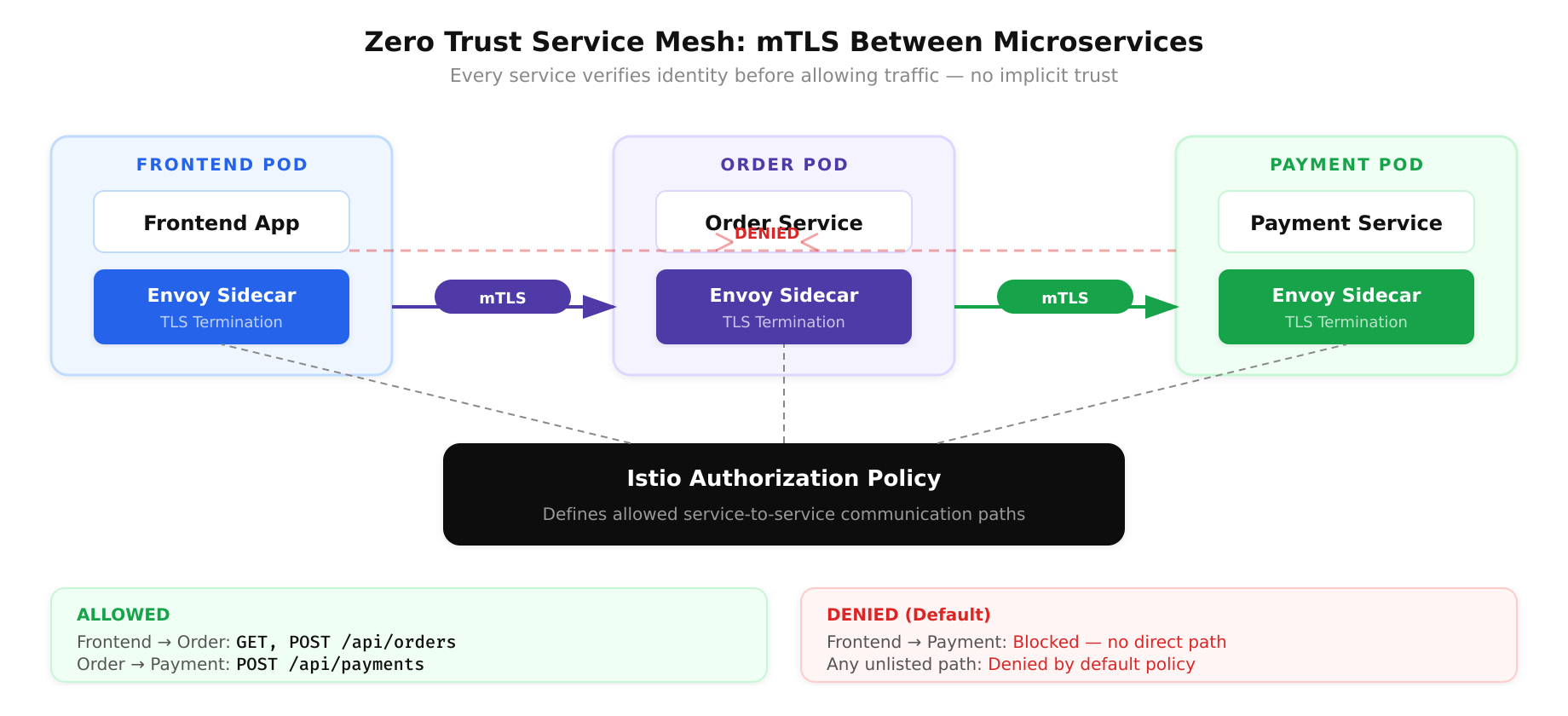
Implementation in Practice
Consider a Kubernetes cluster where microservices communicate over the internal network. In a traditional setup, any pod in the cluster can reach any other pod. In a Zero Trust implementation, a service mesh like Istio or Linkerd enforces mutual TLS (mTLS) between every service pair. Each service has its own identity certificate issued by the mesh’s certificate authority. The sidecar proxy verifies the identity of both the calling and receiving service before allowing traffic to flow. Authorization policies define which services can communicate, on which paths, using which HTTP methods.
A concrete Istio AuthorizationPolicy might look like this: the frontend service can call the order service only on the /api/orders endpoint using POST and GET methods. The order service can call the payment service only on /api/payments using POST. Any other communication path is denied by default. This is “never trust, always verify” applied to east-west service communication.
Principle 2: Least Privilege Access
Least privilege means granting the minimum level of access necessary to perform a specific function, and no more. This applies to users, service accounts, applications, and devices. In Zero Trust, least privilege is enforced dynamically, not just at provisioning time.
- Just-In-Time (JIT) access: Privileges are granted only when needed and automatically revoked after a defined period. An engineer who needs to access a production database to investigate an incident receives temporary credentials that expire after 60 minutes, rather than standing access that persists indefinitely.
- Just-Enough-Access (JEA): Permissions are scoped to the specific resources and actions required. A deployment pipeline service account can push images to the container registry and update Kubernetes deployments in the staging namespace, but it cannot access the production namespace or modify IAM policies.
- Privilege escalation controls: Administrative access requires explicit approval workflows and produces audit logs. Tools like CyberArk, HashiCorp Boundary, or cloud-native privileged access management (PAM) solutions manage the lifecycle of elevated privileges.
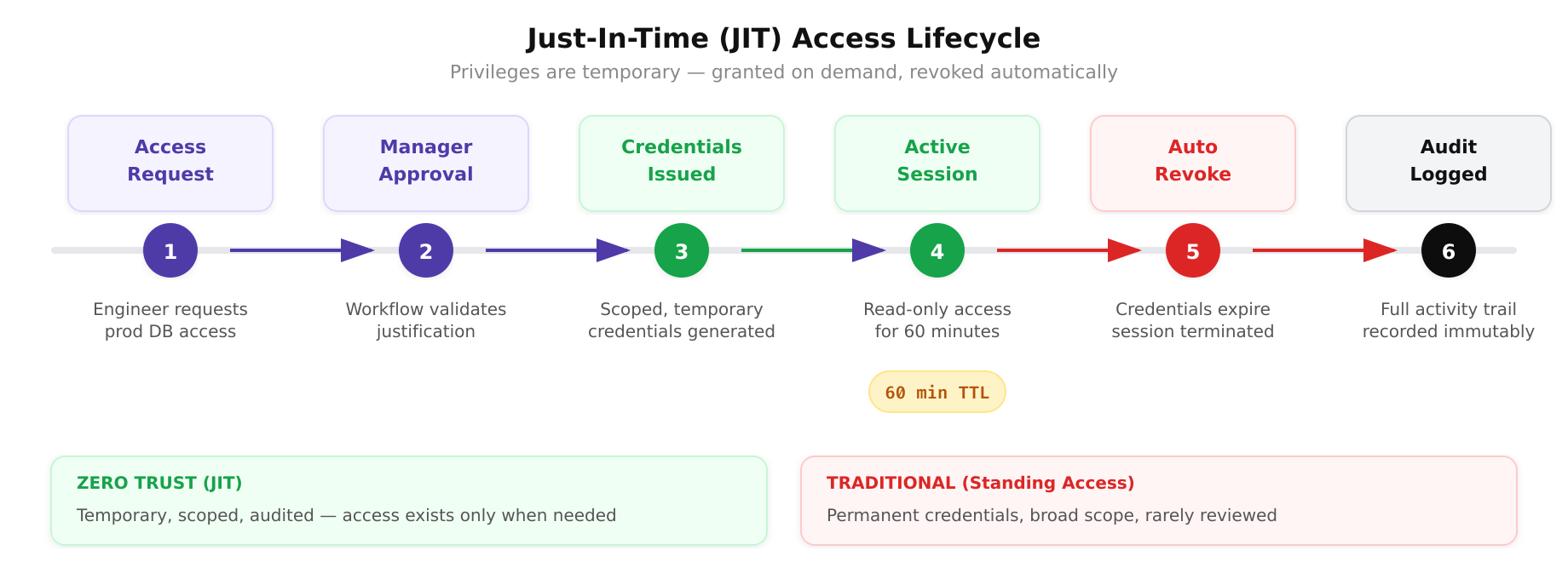
The practical challenge with least privilege is scope creep. Users accumulate permissions over time as they change roles, join new projects, or request access for one-time tasks that are never revoked. Zero Trust addresses this through regular access reviews, automated entitlement management, and policy enforcement that denies access by default.
Principle 3: Assume Breach
Assume breach is the most challenging principle for organizations accustomed to perimeter security. It requires designing every system under the assumption that an attacker already has a foothold in the environment. This is not pessimism; it is realism. The average dwell time for an attacker inside a compromised network, the time between initial access and detection, has historically been measured in months, not hours.
When you assume breach, your security design changes fundamentally:
- Blast radius reduction: Microsegmentation limits how far an attacker can move laterally. If the attacker compromises a web server, they should not be able to reach the database server, the internal DNS infrastructure, or the secrets management system. Each segment is its own trust boundary.
- Encryption everywhere: Data is encrypted in transit and at rest, even within the internal network. If an attacker captures east-west traffic via a network tap or ARP spoofing, the intercepted data is useless without the encryption keys.
- Comprehensive logging: Every access event, every authentication attempt, every network flow is logged and analyzed. Detection capabilities must cover internal activity, not just perimeter events. SIEM platforms and security data lakes ingest these logs and correlate events to identify attack patterns.
- Automated response: When anomalous behavior is detected, automated playbooks can isolate compromised hosts, revoke credentials, and block suspicious network flows without waiting for human intervention.

Principle 4: Microsegmentation
Microsegmentation is the architectural technique that enforces trust boundaries at a granular level. Unlike traditional network segmentation, which divides the network into a handful of broad zones (DMZ, production, development, management), microsegmentation creates security boundaries around individual workloads, applications, or even processes.
Technical Approaches to Microsegmentation
There are multiple technical approaches, and the right choice depends on the environment:
- Network-based microsegmentation: Using VLANs, ACLs, and software-defined networking (SDN) controllers to create fine-grained network segments. VMware NSX and Cisco ACI are examples of platforms that enable this at the network layer.
- Host-based microsegmentation: Using host firewalls (iptables, nftables, Windows Firewall) managed through centralized policy engines. Tools like Illumio and Guardicore deploy agents on each host and enforce traffic policies based on workload identity rather than IP addresses.
- Application-layer microsegmentation: Using service meshes (Istio, Linkerd, Consul Connect) to enforce mTLS and authorization policies between services. This approach operates at Layer 7 and can make access decisions based on HTTP headers, request paths, and gRPC methods.
- Cloud-native microsegmentation: Using cloud security groups, network policies in Kubernetes, and cloud firewall rules to segment workloads. AWS Security Groups, Azure NSGs, and GCP VPC Firewall Rules provide the building blocks for cloud-native microsegmentation.

Effective microsegmentation begins with understanding traffic flows. You cannot write accurate policies without knowing which services communicate with which other services, on which ports, using which protocols. Network flow analysis tools and service dependency mapping are prerequisites for microsegmentation.
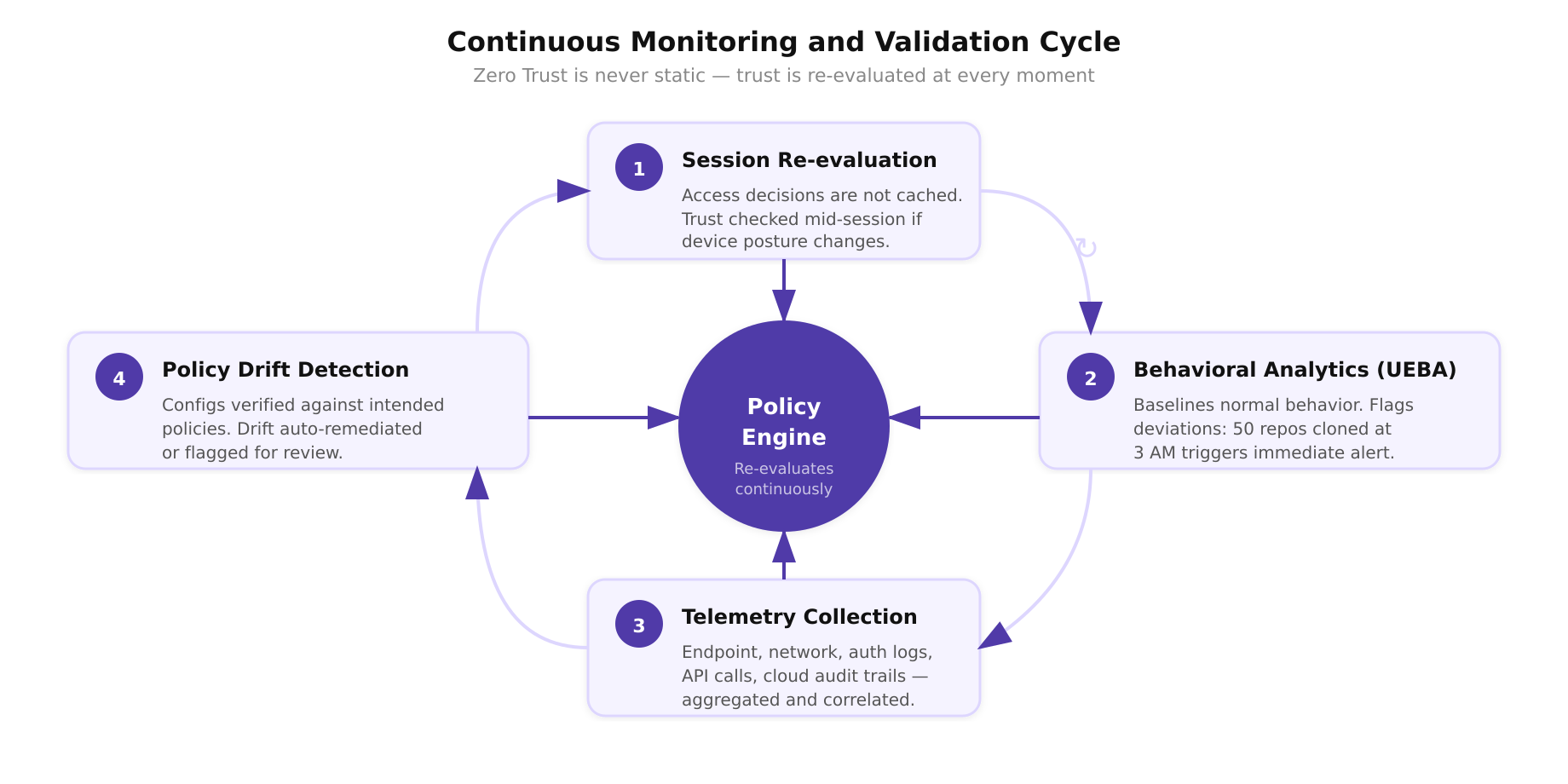
Principle 5: Continuous Monitoring and Validation
Zero Trust is not a static configuration. It is a continuously operating system that re-evaluates trust at every moment. Continuous monitoring encompasses several dimensions:
- Session re-evaluation: Access decisions are not made once and cached. If a device’s posture changes mid-session (for example, its EDR agent reports a suspicious process), the policy engine can revoke the session immediately.
- Behavioral analytics: User and Entity Behavior Analytics (UEBA) platforms establish baselines for normal behavior and flag deviations. An engineer who typically accesses three repositories during business hours but suddenly clones 50 repositories at 3 AM triggers an alert.
- Telemetry collection: Endpoint telemetry, network flow data, authentication logs, API call records, and cloud audit trails are aggregated and correlated. The goal is full visibility into every interaction within the environment.
- Policy drift detection: Automated systems continuously verify that deployed configurations match the intended security policies. Configuration drift, where a firewall rule is manually modified or a security group is inadvertently opened, is detected and either auto-remediated or flagged for review.
Bringing the Principles Together
These principles are interdependent. Least privilege without microsegmentation is undermined by lateral movement. Microsegmentation without continuous monitoring creates blind spots. Continuous monitoring without assume-breach thinking leads to insufficient coverage of internal threats. The principles form a reinforcing system where each one strengthens the others.
For engineers designing or operating infrastructure, the practical takeaway is to evaluate each principle as a checklist against your environment. Where are you relying on implicit trust? Where do accounts hold standing privileges that exceed their operational needs? Where does internal traffic flow uninspected? Where are access decisions made once and never re-evaluated? Each gap represents a concrete, addressable risk, and closing those gaps is the engineering work of Zero Trust.