The scenario simulated here is TradeLink Maritime, a shipping consortium operating a Hyperledger Fabric 2.5 network across three data centers (London, Frankfurt, Singapore) with 3 organizations, 5 orderers, 6 peers, and 4 RPC gateways serving 200+ client applications processing bill of lading transactions.
Understanding Node Roles and Responsibilities
A production blockchain network is not a monolith. Each node type serves a specific function in the transaction lifecycle, and mixing roles on the same infrastructure creates resource contention that degrades performance under load. The four primary node types across both Fabric and Ethereum based networks are orderers (or validators), peers (or full nodes), certificate authorities, and RPC/gateway nodes.
In Hyperledger Fabric, orderer nodes manage the Raft consensus protocol and produce blocks. They never execute chaincode or store world state. Peer nodes execute chaincode during endorsement, maintain the full ledger, and serve queries. RPC gateway nodes act as client facing proxies, routing transactions to the correct endorsers and orderers based on the endorsement policy.
, Free to use, share it in your presentations, blogs, or learning materials.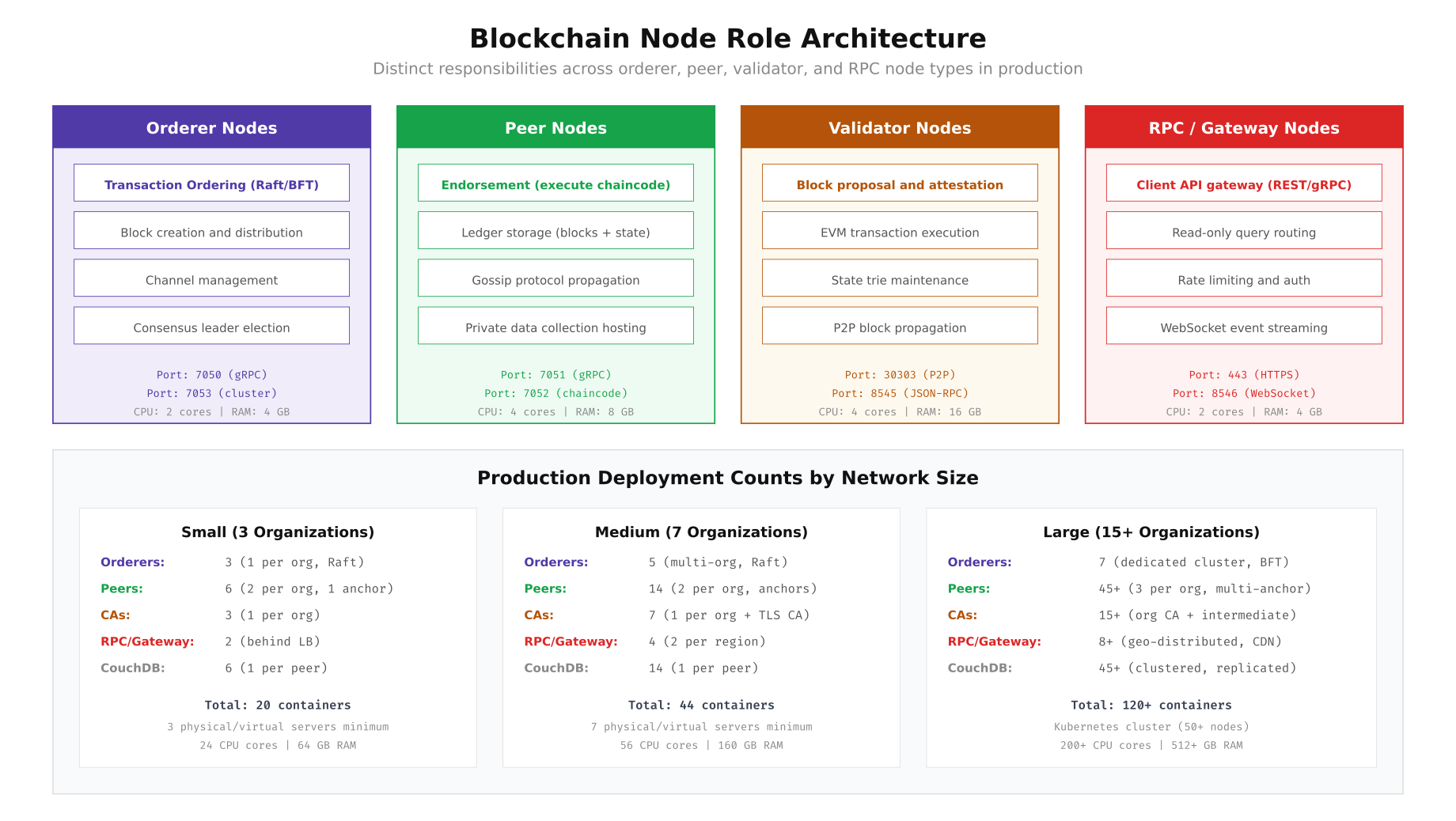
The above illustration maps out the four core node types and their distinct responsibilities. Orderer nodes handle transaction ordering via Raft consensus on ports 7050 and 7053, while peer nodes perform chaincode execution and ledger storage on ports 7051 and 7052. Validator nodes in Ethereum based networks manage block proposal and EVM execution, and RPC gateways provide the client facing API layer. The bottom section shows how deployment counts scale from 20 containers for a 3-org network to 120+ containers for large consortiums.
Orderer Node Configuration for Raft Consensus
TradeLink Maritime runs 5 Raft orderers distributed across three data centers. The orderer configuration in orderer.yaml controls consensus timeouts, batch sizes, and cluster communication. Start by generating the orderer genesis block and configuring each node.
# Generate orderer genesis block using configtxgen
configtxgen -profile TradeLink5OrgRaft \
-channelID system-channel \
-outputBlock /etc/hyperledger/fabric/genesis.block
# Orderer environment configuration (orderer0, London)
cat <<EOF > /etc/hyperledger/fabric/orderer.yaml
General:
ListenAddress: 0.0.0.0
ListenPort: 7050
TLS:
Enabled: true
PrivateKey: /etc/hyperledger/fabric/tls/server.key
Certificate: /etc/hyperledger/fabric/tls/server.crt
RootCAs:
- /etc/hyperledger/fabric/tls/ca.crt
ClientAuthRequired: true
ClientRootCAs:
- /etc/hyperledger/fabric/tls/ca.crt
Cluster:
ListenAddress: 0.0.0.0
ListenPort: 7053
ServerCertificate: /etc/hyperledger/fabric/tls/server.crt
ServerPrivateKey: /etc/hyperledger/fabric/tls/server.key
ClientCertificate: /etc/hyperledger/fabric/tls/server.crt
ClientPrivateKey: /etc/hyperledger/fabric/tls/server.key
RootCAs:
- /etc/hyperledger/fabric/tls/ca.crt
BootstrapMethod: file
BootstrapFile: /etc/hyperledger/fabric/genesis.block
LocalMSPDir: /etc/hyperledger/fabric/msp
LocalMSPID: OrdererMSP
FileLedger:
Location: /var/hyperledger/production/orderer
MaxRecvMsgSize: 104857600
MaxSendMsgSize: 104857600
Keepalive:
ServerMinInterval: 60s
ServerInterval: 7200s
ServerTimeout: 20s
Consensus:
WALDir: /var/hyperledger/production/orderer/etcdraft/wal
SnapDir: /var/hyperledger/production/orderer/etcdraft/snapshot
TickInterval: 500ms
ElectionTick: 10
HeartbeatTick: 1
MaxInflightBlocks: 5
SnapshotIntervalSize: 20971520
EOF
# Start orderer process with resource limits
systemd-run --scope -p MemoryMax=8G -p CPUQuota=200% \
orderer start 2>&1 | tee /var/log/orderer/orderer0.logThe Raft configuration uses a 500ms tick interval with an election timeout of 10 ticks (5 seconds). This balance works well for cross-datacenter deployments where London to Frankfurt latency averages 8ms and London to Singapore averages 170ms. The MaxInflightBlocks setting of 5 allows the leader to pipeline block distribution without overwhelming followers.
Peer Node Deployment with CouchDB State Database
Each organization in the TradeLink consortium runs two peers: one anchor peer that participates in cross-org gossip and one non-anchor peer for redundancy. The peer and CouchDB containers are colocated on the same host for low latency state queries.
# Peer core configuration (peer0.org1, London Rack A)
cat <<EOF > /etc/hyperledger/fabric/core.yaml
peer:
id: peer0.org1.tradelink.net
listenAddress: 0.0.0.0:7051
chaincodeListenAddress: 0.0.0.0:7052
address: peer0.org1.tradelink.net:7051
addressAutoDetect: false
networkId: tradelink-prod
gossip:
bootstrap: peer1.org1.tradelink.net:7051
useLeaderElection: true
orgLeader: false
membershipTrackerInterval: 5s
endpoint: peer0.org1.tradelink.net:7051
externalEndpoint: peer0.org1.tradelink.net:7051
maxBlockCountToStore: 100
maxPropagationBurstLatency: 10ms
maxPropagationBurstSize: 10
propagateIterations: 1
propagatePeerNum: 3
pullInterval: 4s
pullPeerNum: 3
state:
enabled: true
checkInterval: 10s
responseTimeout: 3s
batchSize: 10
blockBufferSize: 200
maxRetries: 3
tls:
enabled: true
clientAuthRequired: true
cert:
file: /etc/hyperledger/fabric/tls/server.crt
key:
file: /etc/hyperledger/fabric/tls/server.key
rootcert:
file: /etc/hyperledger/fabric/tls/ca.crt
clientRootCAs:
files:
- /etc/hyperledger/fabric/tls/ca.crt
localMspId: Org1MSP
ledger:
state:
stateDatabase: CouchDB
couchDBConfig:
couchDBAddress: localhost:5984
username: admin
password: \${COUCHDB_PASSWORD}
maxRetries: 3
maxRetriesOnStartup: 20
requestTimeout: 35s
createGlobalChangesDB: false
cacheSize: 128
history:
enableHistoryDatabase: true
chaincode:
builder: ccaas
executetimeout: 30s
operations:
listenAddress: 0.0.0.0:9443
tls:
enabled: true
cert:
file: /etc/hyperledger/fabric/tls/server.crt
key:
file: /etc/hyperledger/fabric/tls/server.key
metrics:
provider: prometheus
EOF
# CouchDB configuration for the peer's state database
cat <<EOF > /opt/couchdb/etc/local.ini
[couchdb]
max_dbs_open = 500
os_process_timeout = 5000
[chttpd]
port = 5984
bind_address = 127.0.0.1
max_http_request_size = 67108864
[admins]
admin = \${COUCHDB_PASSWORD}
[log]
level = warning
file = /var/log/couchdb/couchdb.log
[compactions]
_default = [{db_fragmentation, "70%"}, {view_fragmentation, "60%"}]
EOF
# Start CouchDB then peer with health checks
systemctl start couchdb
until curl -sf http://127.0.0.1:5984/_up; do sleep 1; done
echo "CouchDB ready, starting peer..."
peer node start 2>&1 | tee /var/log/peer/peer0-org1.logThe gossip configuration deserves attention. Setting useLeaderElection: true with orgLeader: false enables dynamic leader election for the gossip protocol within each organization. The propagatePeerNum: 3 setting means each peer forwards received blocks to 3 other peers, creating rapid dissemination across the network. The CouchDB instance binds to localhost only, preventing external access to the state database.
Transaction Flow Through Node Types
Understanding how a transaction flows through different node types is essential for diagnosing latency bottlenecks and planning capacity. In Hyperledger Fabric, the execute-order-validate model separates transaction execution (endorsement by peers) from ordering (orderer consensus) and validation (committing peers). Each step involves different node types with different performance characteristics.
, Free to use, share it in your presentations, blogs, or learning materials.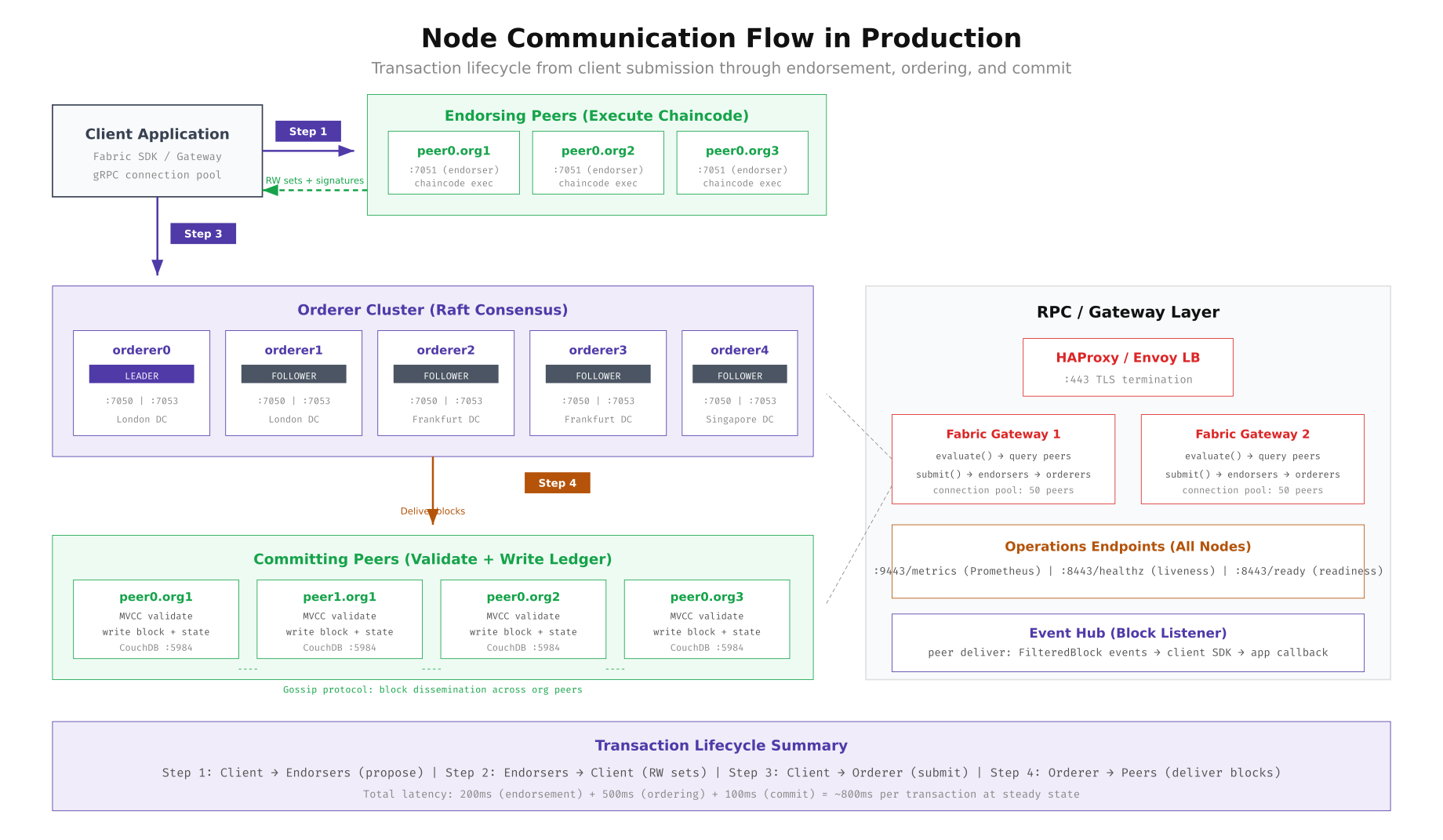
This diagram traces a transaction through all four steps. The client submits a proposal to endorsing peers (Step 1), receives signed read-write sets back (Step 2), forwards the endorsed transaction to the orderer cluster (Step 3), and then orderers deliver blocks to all committing peers (Step 4). The RPC gateway layer on the right shows how HAProxy or Envoy load balancers front the Fabric Gateway service, which internally manages connection pools to peers and orderers. Total steady state latency for this flow is approximately 800ms: 200ms for endorsement, 500ms for ordering, and 100ms for commit.
Fabric Gateway Service Configuration
The Fabric Gateway service (introduced in Fabric 2.4) simplifies client interaction by handling endorser selection and transaction submission internally. Deploy it as a separate service rather than embedding it in peer processes.
# Fabric Gateway connection profile for TradeLink
cat <<EOF > /etc/hyperledger/gateway/connection-tradelink.yaml
name: TradeLink Maritime Network
version: 1.0.0
client:
organization: Org1
connection:
timeout:
peer:
endorser: 300
eventHub: 300
eventReg: 300
orderer: 300
channels:
shipping-channel:
orderers:
- orderer0.tradelink.net
- orderer1.tradelink.net
- orderer2.tradelink.net
peers:
peer0.org1.tradelink.net:
endorsingPeer: true
chaincodeQuery: true
ledgerQuery: true
eventSource: true
peer0.org2.tradelink.net:
endorsingPeer: true
chaincodeQuery: true
ledgerQuery: true
eventSource: false
peer0.org3.tradelink.net:
endorsingPeer: true
chaincodeQuery: false
ledgerQuery: false
eventSource: false
organizations:
Org1:
mspid: Org1MSP
peers:
- peer0.org1.tradelink.net
- peer1.org1.tradelink.net
certificateAuthorities:
- ca.org1.tradelink.net
peers:
peer0.org1.tradelink.net:
url: grpcs://peer0.org1.tradelink.net:7051
grpcOptions:
ssl-target-name-override: peer0.org1.tradelink.net
hostnameOverride: peer0.org1.tradelink.net
grpc.keepalive_time_ms: 600000
grpc.max_receive_message_length: 104857600
tlsCACerts:
path: /etc/hyperledger/fabric/tls/ca-org1.crt
orderers:
orderer0.tradelink.net:
url: grpcs://orderer0.tradelink.net:7050
grpcOptions:
ssl-target-name-override: orderer0.tradelink.net
grpc.keepalive_time_ms: 600000
tlsCACerts:
path: /etc/hyperledger/fabric/tls/ca-orderer.crt
EOF
# HAProxy configuration for gateway load balancing
cat <<EOF > /etc/haproxy/haproxy.cfg
global
maxconn 4096
log /dev/log local0
defaults
mode tcp
timeout connect 5s
timeout client 300s
timeout server 300s
option tcplog
frontend ft_gateway
bind *:443 ssl crt /etc/haproxy/certs/gateway.pem
default_backend bk_gateway
backend bk_gateway
balance leastconn
option httpchk GET /healthz
http-check expect status 200
server gw0 gateway-rpc-0:8443 check inter 3s fall 3 rise 2 ssl verify required ca-file /etc/haproxy/certs/ca.crt
server gw1 gateway-rpc-1:8443 check inter 3s fall 3 rise 2 ssl verify required ca-file /etc/haproxy/certs/ca.crt
server gw2 gateway-rpc-2:8443 check inter 3s fall 3 rise 2 ssl verify required ca-file /etc/haproxy/certs/ca.crt backup
server gw3 gateway-rpc-3:8443 check inter 3s fall 3 rise 2 ssl verify required ca-file /etc/haproxy/certs/ca.crt backup
frontend ft_grpc_orderer
bind *:7050 ssl crt /etc/haproxy/certs/orderer.pem
default_backend bk_orderer
backend bk_orderer
balance roundrobin
server ord0 orderer0.tradelink.net:7050 check inter 5s ssl verify required ca-file /etc/haproxy/certs/ca-orderer.crt
server ord1 orderer1.tradelink.net:7050 check inter 5s ssl verify required ca-file /etc/haproxy/certs/ca-orderer.crt
server ord2 orderer2.tradelink.net:7050 check inter 5s ssl verify required ca-file /etc/haproxy/certs/ca-orderer.crt
EOF
systemctl restart haproxy
haproxy -c -f /etc/haproxy/haproxy.cfg && echo "HAProxy config valid"Node Placement Strategy Across Data Centers
Placing nodes across racks and data centers requires balancing latency against fault tolerance. The key principle is that no single rack failure, power feed outage, or network partition should cause the network to lose consensus or the ability to process transactions. For TradeLink Maritime, orderers are spread across all three data centers, with London hosting the Raft leader under normal conditions.
, Free to use, share it in your presentations, blogs, or learning materials.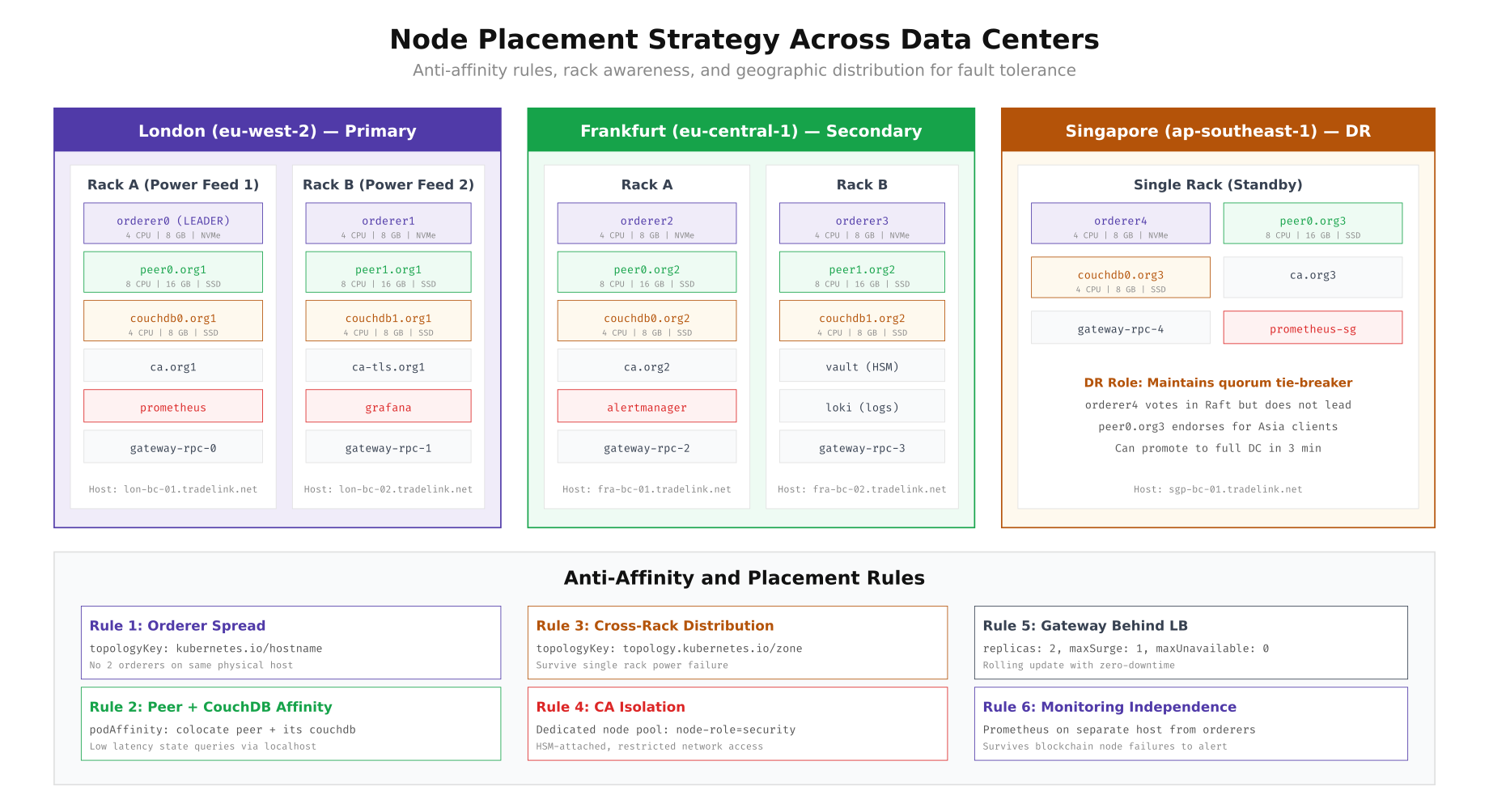
The layout above shows how TradeLink Maritime distributes nodes across London (primary, 2 racks), Frankfurt (secondary, 2 racks), and Singapore (DR, 1 rack). Each rack runs on a separate power feed, so a single power failure only impacts half the nodes in any given data center. The anti-affinity rules at the bottom enforce placement constraints: orderers never share a physical host, peer and CouchDB containers are colocated for performance, CAs run on dedicated HSM attached nodes, and monitoring systems remain on separate infrastructure to survive blockchain node failures.
Kubernetes Anti-Affinity Manifests
When deploying on Kubernetes, pod anti-affinity and node affinity rules enforce the placement strategy declaratively. The following manifests show the orderer StatefulSet with cross-zone spreading and the peer Deployment with CouchDB colocation.
# Orderer StatefulSet with anti-affinity (orderer-statefulset.yaml)
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: orderer
namespace: fabric-orderers
spec:
replicas: 5
serviceName: orderer-cluster
podManagementPolicy: Parallel
selector:
matchLabels:
app: orderer
template:
metadata:
labels:
app: orderer
network: tradelink
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- orderer
topologyKey: kubernetes.io/hostname
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- orderer
topologyKey: topology.kubernetes.io/zone
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node-role
operator: In
values:
- blockchain
- key: storage-type
operator: In
values:
- nvme
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: orderer
containers:
- name: orderer
image: hyperledger/fabric-orderer:2.5.12
ports:
- containerPort: 7050
name: grpc
- containerPort: 7053
name: cluster
- containerPort: 9443
name: metrics
resources:
requests:
cpu: "2"
memory: 4Gi
limits:
cpu: "4"
memory: 8Gi
volumeMounts:
- name: orderer-data
mountPath: /var/hyperledger/production
- name: orderer-tls
mountPath: /etc/hyperledger/fabric/tls
readOnly: true
- name: orderer-msp
mountPath: /etc/hyperledger/fabric/msp
readOnly: true
livenessProbe:
httpGet:
path: /healthz
port: 9443
scheme: HTTPS
initialDelaySeconds: 30
periodSeconds: 10
readinessProbe:
httpGet:
path: /healthz
port: 9443
scheme: HTTPS
initialDelaySeconds: 10
periodSeconds: 5
volumeClaimTemplates:
- metadata:
name: orderer-data
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: nvme-fast
resources:
requests:
storage: 100Gi
---
# Peer + CouchDB pod affinity (peer-deployment.yaml)
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: peer0-org1
namespace: fabric-org1
spec:
replicas: 1
serviceName: peer0-org1
selector:
matchLabels:
app: peer
org: org1
peer-id: peer0
template:
metadata:
labels:
app: peer
org: org1
peer-id: peer0
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- peer
- key: org
operator: In
values:
- org1
topologyKey: kubernetes.io/hostname
containers:
- name: peer
image: hyperledger/fabric-peer:2.5.12
ports:
- containerPort: 7051
name: grpc
- containerPort: 7052
name: chaincode
- containerPort: 9443
name: metrics
resources:
requests:
cpu: "4"
memory: 8Gi
limits:
cpu: "8"
memory: 16Gi
volumeMounts:
- name: peer-data
mountPath: /var/hyperledger/production
- name: couchdb
image: couchdb:3.3
ports:
- containerPort: 5984
resources:
requests:
cpu: "2"
memory: 4Gi
limits:
cpu: "4"
memory: 8Gi
env:
- name: COUCHDB_USER
value: admin
- name: COUCHDB_PASSWORD
valueFrom:
secretKeyRef:
name: couchdb-secret
key: password
volumeMounts:
- name: couchdb-data
mountPath: /opt/couchdb/data
volumeClaimTemplates:
- metadata:
name: peer-data
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: ssd-retain
resources:
requests:
storage: 200Gi
- metadata:
name: couchdb-data
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: ssd-retain
resources:
requests:
storage: 100GiThe orderer StatefulSet uses topologySpreadConstraints with maxSkew: 1 to ensure orderers distribute evenly across availability zones. The requiredDuringSchedulingIgnoredDuringExecution anti-affinity guarantees no two orderers land on the same physical host. For peers, the CouchDB sidecar container runs in the same pod, eliminating network latency for state queries while still maintaining separate persistent volume claims for independent scaling of block storage and state database storage.
Scaling Patterns for Each Node Type
Not all node types scale the same way. Peers can be added horizontally with minimal coordination. Orderers require careful Raft membership changes. RPC gateways scale freely behind load balancers. Understanding the constraints and triggers for each type prevents both over provisioning (wasted infrastructure cost) and under provisioning (degraded performance or consensus instability).
, Free to use, share it in your presentations, blogs, or learning materials.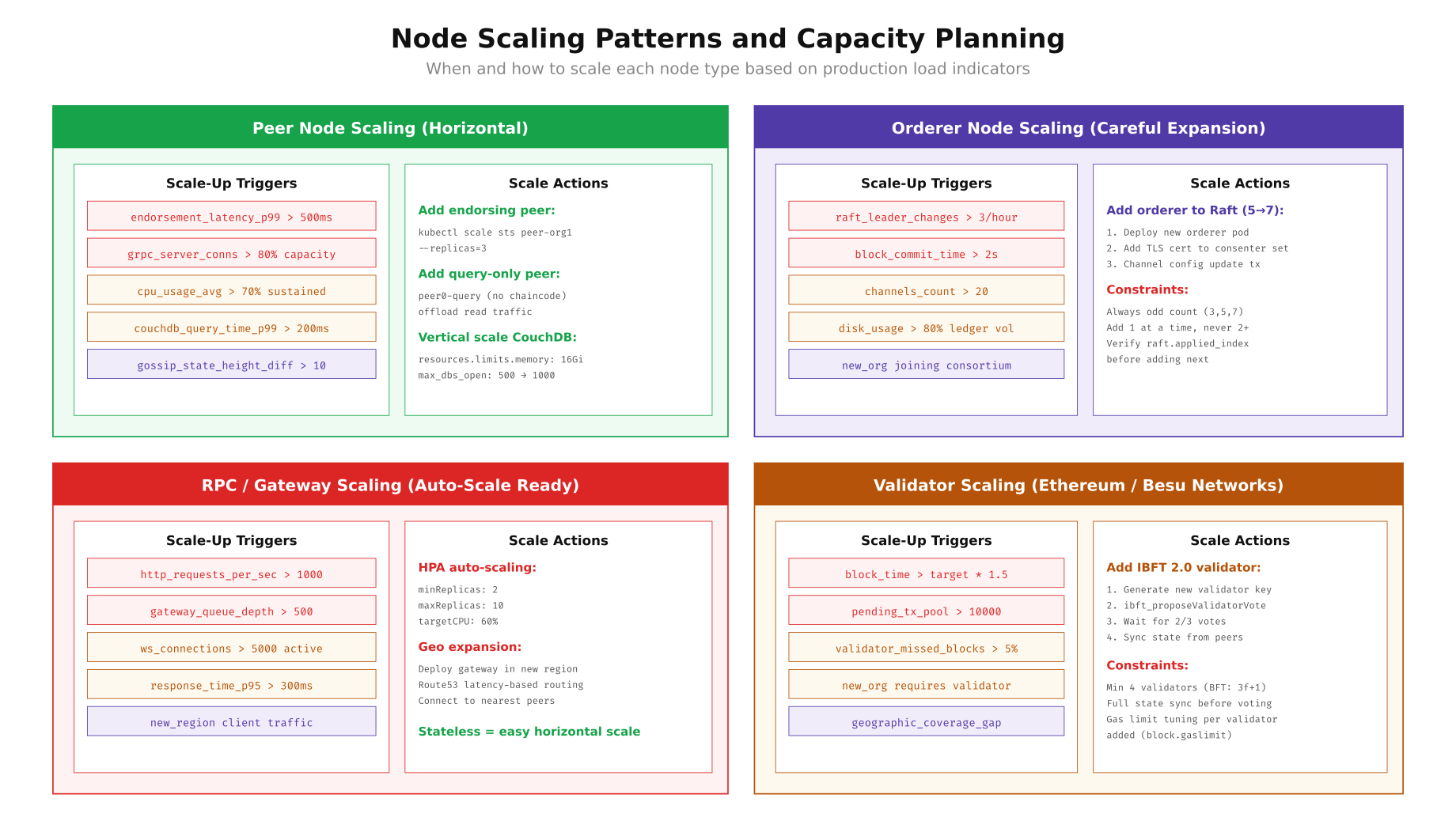
As shown above, each node type has different scaling triggers and constraints. Peers scale horizontally when endorsement latency exceeds 500ms or gRPC connections hit 80% capacity. Orderers scale carefully in odd numbers (3, 5, 7) with one at a time additions and Raft index verification between each. RPC gateways are stateless and can auto scale via Kubernetes HPA. Validators in Ethereum networks require a governance vote (2/3 majority in IBFT 2.0) before joining the validator set.
Adding a New Orderer to the Raft Cluster
When TradeLink Maritime needs to add a 6th orderer (for example, when a new partner organization in Dubai joins the consortium), the process involves deploying the new orderer, adding its TLS certificate to the consenter set, and then submitting a channel configuration update.
# Step 1: Deploy the new orderer node (orderer5 in Dubai)
kubectl apply -f orderer5-statefulset.yaml -n fabric-orderers
# Wait for the pod to be ready and synced
kubectl wait --for=condition=ready pod/orderer-5 -n fabric-orderers --timeout=120s
# Step 2: Fetch the current channel configuration
peer channel fetch config config_block.pb \
-o orderer0.tradelink.net:7050 \
-c shipping-channel \
--tls --cafile /etc/hyperledger/fabric/tls/ca-orderer.crt
# Decode the config block
configtxlator proto_decode --input config_block.pb \
--type common.Block --output config_block.json
# Extract the config
jq '.data.data[0].payload.data.config' config_block.json > config.json
cp config.json modified_config.json
# Step 3: Add new orderer to the consenter set
# Extract orderer5 TLS certificate (base64 encoded)
ORDERER5_TLS_CERT=$(base64 -w 0 /etc/hyperledger/fabric/tls/orderer5-server.crt)
# Add to consenters array using jq
jq '.channel_group.groups.Orderer.values.ConsensusType.value.metadata.consenters += [{
"host": "orderer5.tradelink.net",
"port": 7050,
"client_tls_cert": "'$ORDERER5_TLS_CERT'",
"server_tls_cert": "'$ORDERER5_TLS_CERT'"
}]' modified_config.json > modified_config_updated.json
# Also add to orderer addresses
jq '.channel_group.values.OrdererAddresses.value.addresses += [
"orderer5.tradelink.net:7050"
]' modified_config_updated.json > modified_config_final.json
# Step 4: Compute the config update delta
configtxlator proto_encode --input config.json \
--type common.Config --output config.pb
configtxlator proto_encode --input modified_config_final.json \
--type common.Config --output modified_config.pb
configtxlator compute_update --channel_id shipping-channel \
--original config.pb --updated modified_config.pb \
--output config_update.pb
# Wrap in envelope
configtxlator proto_decode --input config_update.pb \
--type common.ConfigUpdate --output config_update.json
echo '{"payload":{"header":{"channel_header":{"channel_id":"shipping-channel","type":2}},"data":{"config_update":'$(cat config_update.json)'}}}' | \
jq . > config_update_envelope.json
configtxlator proto_encode --input config_update_envelope.json \
--type common.Envelope --output config_update_envelope.pb
# Step 5: Collect signatures from majority of existing orderer orgs
peer channel signconfigtx -f config_update_envelope.pb
# Submit the update
peer channel update -f config_update_envelope.pb \
-o orderer0.tradelink.net:7050 \
-c shipping-channel \
--tls --cafile /etc/hyperledger/fabric/tls/ca-orderer.crt
# Step 6: Verify the new orderer joined the cluster
peer channel fetch config verify_block.pb \
-o orderer5.tradelink.net:7050 \
-c shipping-channel \
--tls --cafile /etc/hyperledger/fabric/tls/ca-orderer.crt
echo "Orderer5 successfully added to Raft cluster"
# Verify Raft cluster health (check applied index convergence)
for i in 0 1 2 3 4 5; do
echo "orderer${i}:"
curl -sk https://orderer${i}.tradelink.net:9443/metrics | \
grep -E "etcdraft_cluster_size|consensus_etcdraft_applied_index"
doneAfter adding the orderer, always verify that the consensus_etcdraft_applied_index converges across all nodes. A lagging applied index on the new orderer means it is still catching up with the block history, and you should not add another orderer until convergence is complete. The cluster size metric should report 6 across all nodes after the configuration update takes effect.
Horizontal Peer Scaling and Query Offloading
When Org1’s peers hit capacity during peak bill of lading processing, add a query-only peer that does not participate in endorsement. This offloads read queries from the endorsing peers while maintaining the full ledger for audit purposes.
# Scale the peer StatefulSet to add a third peer
kubectl scale sts peer0-org1 --replicas=3 -n fabric-org1
# Alternatively, deploy a dedicated query peer
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: peer-query-org1
namespace: fabric-org1
spec:
replicas: 1
serviceName: peer-query-org1
selector:
matchLabels:
app: peer-query
org: org1
template:
metadata:
labels:
app: peer-query
org: org1
spec:
containers:
- name: peer
image: hyperledger/fabric-peer:2.5.12
env:
- name: CORE_PEER_ID
value: peer-query.org1.tradelink.net
- name: CORE_PEER_GOSSIP_USELEADERELECTION
value: "false"
- name: CORE_PEER_GOSSIP_ORGLEADER
value: "false"
- name: CORE_PEER_GOSSIP_BOOTSTRAP
value: peer0-org1-0.peer0-org1.fabric-org1:7051
- name: CORE_PEER_CHAINCODEADDRESS
value: ""
resources:
requests:
cpu: "2"
memory: 4Gi
limits:
cpu: "4"
memory: 8Gi
ports:
- containerPort: 7051
name: grpc
- name: couchdb
image: couchdb:3.3
resources:
requests:
cpu: "1"
memory: 2Gi
EOF
# Configure HAProxy to route read-only queries to the query peer
cat <<EOF >> /etc/haproxy/haproxy.cfg
backend bk_peer_query_org1
balance roundrobin
option httpchk GET /healthz
http-check expect status 200
server peer0 peer0-org1-0.fabric-org1:7051 check ssl
server peer1 peer0-org1-1.fabric-org1:7051 check ssl
server peer-query peer-query-org1-0.fabric-org1:7051 check ssl
EOF
# Verify the query peer synced the ledger
kubectl exec -it peer-query-org1-0 -n fabric-org1 -- \
peer channel getinfo -c shipping-channel
# Compare block height with endorsing peers
for peer in peer0-org1-0 peer0-org1-1 peer-query-org1-0; do
echo "${peer}:"
kubectl exec -it ${peer} -n fabric-org1 -- \
peer channel getinfo -c shipping-channel 2>&1 | grep "Blockchain info"
doneValidator and RPC Node Topology for Ethereum Networks
For organizations running Besu or Geth based networks, the topology differs from Fabric. Validator nodes replace orderers as the consensus participants, and RPC nodes serve as the public interface. TradeLink’s subsidiary running a Besu IBFT 2.0 network for port authority document verification uses the following topology.
# Besu validator node configuration (validator1, Frankfurt)
cat <<EOF > /etc/besu/config.toml
data-path="/var/lib/besu/data"
genesis-file="/etc/besu/genesis.json"
# Network
p2p-enabled=true
p2p-host="0.0.0.0"
p2p-port=30303
discovery-enabled=false
bootnodes=[
"enode://abc123...@validator0.tradelink.net:30303",
"enode://def456...@validator2.tradelink.net:30303",
"enode://ghi789...@validator3.tradelink.net:30303"
]
# RPC (disabled on validators for security)
rpc-http-enabled=false
rpc-ws-enabled=false
graphql-http-enabled=false
# Metrics
metrics-enabled=true
metrics-host="0.0.0.0"
metrics-port=9545
metrics-protocol="PROMETHEUS"
# Mining / Validator
miner-enabled=true
miner-coinbase="0x1234567890abcdef1234567890abcdef12345678"
# Performance
tx-pool-max-size=4096
tx-pool-retention-hours=999
Xplugin-rocksdb-max-open-files=1024
EOF
# Besu RPC node configuration (rpc-node1, public facing)
cat <<EOF > /etc/besu/rpc-config.toml
data-path="/var/lib/besu/rpc-data"
genesis-file="/etc/besu/genesis.json"
sync-mode="SNAP"
# Network
p2p-enabled=true
p2p-host="0.0.0.0"
p2p-port=30303
# RPC (enabled on RPC nodes)
rpc-http-enabled=true
rpc-http-host="0.0.0.0"
rpc-http-port=8545
rpc-http-cors-origins=["*"]
rpc-http-api=["ETH","NET","WEB3","TXPOOL"]
rpc-http-max-active-connections=200
rpc-http-max-batch-size=50
rpc-ws-enabled=true
rpc-ws-host="0.0.0.0"
rpc-ws-port=8546
rpc-ws-api=["ETH","NET","WEB3"]
rpc-ws-max-active-connections=500
# Do NOT enable admin, debug, miner APIs on public RPC
# rpc-http-api=["ADMIN","DEBUG","MINER"] # NEVER on public nodes
# Metrics
metrics-enabled=true
metrics-host="0.0.0.0"
metrics-port=9545
# NOT a validator
miner-enabled=false
EOF
# NGINX rate limiting for RPC nodes
cat <<EOF > /etc/nginx/conf.d/besu-rpc.conf
limit_req_zone \$binary_remote_addr zone=rpc_limit:10m rate=50r/s;
limit_conn_zone \$binary_remote_addr zone=rpc_conn:10m;
upstream besu_rpc {
least_conn;
server rpc-node0.tradelink.net:8545 max_fails=3 fail_timeout=10s;
server rpc-node1.tradelink.net:8545 max_fails=3 fail_timeout=10s;
server rpc-node2.tradelink.net:8545 max_fails=3 fail_timeout=10s backup;
}
server {
listen 443 ssl;
server_name rpc.tradelink.net;
ssl_certificate /etc/nginx/certs/rpc.crt;
ssl_certificate_key /etc/nginx/certs/rpc.key;
ssl_protocols TLSv1.3;
location /rpc {
limit_req zone=rpc_limit burst=100 nodelay;
limit_conn rpc_conn 20;
proxy_pass http://besu_rpc;
proxy_set_header X-Real-IP \$remote_addr;
proxy_http_version 1.1;
proxy_set_header Upgrade \$http_upgrade;
proxy_set_header Connection "upgrade";
proxy_read_timeout 300s;
}
}
EOF
nginx -t && systemctl reload nginxThe critical security distinction is that validator nodes have all RPC interfaces disabled. They communicate only via P2P (port 30303) and expose Prometheus metrics (port 9545) to the internal monitoring network. The RPC nodes expose HTTP and WebSocket APIs but explicitly exclude admin, debug, and miner API namespaces. NGINX provides rate limiting at 50 requests per second per client IP with a burst buffer of 100, protecting the RPC nodes from overload.
Monitoring Node Health Across the Topology
With nodes distributed across data centers and roles, monitoring must cover both individual node health and cross-node relationships (Raft leader election, gossip state height, endorsement latency). Set up Prometheus scrape targets for each node type and create role-specific dashboards.
# Prometheus scrape configuration for all node types
cat <<EOF > /etc/prometheus/scrape-blockchain.yml
scrape_configs:
- job_name: fabric-orderers
scheme: https
tls_config:
ca_file: /etc/prometheus/certs/ca-orderer.crt
cert_file: /etc/prometheus/certs/prometheus.crt
key_file: /etc/prometheus/certs/prometheus.key
static_configs:
- targets:
- orderer0.tradelink.net:9443
- orderer1.tradelink.net:9443
- orderer2.tradelink.net:9443
- orderer3.tradelink.net:9443
- orderer4.tradelink.net:9443
labels:
role: orderer
network: tradelink
- job_name: fabric-peers
scheme: https
tls_config:
ca_file: /etc/prometheus/certs/ca-peer.crt
static_configs:
- targets:
- peer0.org1.tradelink.net:9443
- peer1.org1.tradelink.net:9443
- peer0.org2.tradelink.net:9443
- peer1.org2.tradelink.net:9443
- peer0.org3.tradelink.net:9443
labels:
role: peer
network: tradelink
- job_name: fabric-gateways
scheme: https
static_configs:
- targets:
- gateway-rpc-0.tradelink.net:9443
- gateway-rpc-1.tradelink.net:9443
- gateway-rpc-2.tradelink.net:9443
- gateway-rpc-3.tradelink.net:9443
labels:
role: gateway
network: tradelink
- job_name: couchdb
scheme: http
metrics_path: /_node/_local/_prometheus
static_configs:
- targets:
- couchdb0-org1.tradelink.net:5984
- couchdb1-org1.tradelink.net:5984
- couchdb0-org2.tradelink.net:5984
- couchdb1-org2.tradelink.net:5984
- couchdb0-org3.tradelink.net:5984
labels:
role: statedb
EOF
# Alert rules specific to node topology
cat <<EOF > /etc/prometheus/rules/node-topology-alerts.yml
groups:
- name: orderer_topology
rules:
- alert: RaftLeaderLost
expr: max(consensus_etcdraft_is_leader{job="fabric-orderers"}) == 0
for: 10s
labels:
severity: critical
annotations:
summary: "No Raft leader elected in TradeLink orderer cluster"
- alert: OrdrerClusterDegraded
expr: count(up{job="fabric-orderers"} == 1) < 3
for: 30s
labels:
severity: critical
annotations:
summary: "Orderer cluster below quorum threshold ({{ \$value }}/5)"
- alert: PeerLedgerLag
expr: |
max(ledger_blockchain_height{job="fabric-peers"})
- min(ledger_blockchain_height{job="fabric-peers"}) > 10
for: 2m
labels:
severity: warning
annotations:
summary: "Peer ledger height divergence > 10 blocks"
- alert: GatewayHighLatency
expr: |
histogram_quantile(0.99,
rate(grpc_server_handling_seconds_bucket{job="fabric-gateways"}[5m])
) > 2
for: 5m
labels:
severity: warning
annotations:
summary: "Gateway P99 latency > 2s"
- alert: CouchDBHighRequestTime
expr: |
rate(couchdb_httpd_request_time_sum[5m])
/ rate(couchdb_httpd_request_time_count[5m]) > 0.2
for: 5m
labels:
severity: warning
annotations:
summary: "CouchDB average request time > 200ms"
EOF
# Verify alert rules syntax
promtool check rules /etc/prometheus/rules/node-topology-alerts.yml
systemctl reload prometheusThe alert rules target specific topology concerns: Raft leader loss (no ordering possible), cluster degradation below quorum threshold, peer ledger height divergence (gossip issues), gateway latency spikes, and CouchDB performance degradation. Each alert has a carefully tuned for duration to avoid false positives while catching genuine issues quickly. The CouchDB metric endpoint at /_node/_local/_prometheus requires CouchDB 3.3+ and provides detailed database operation metrics.
Network Segmentation for Node Security
Each node type should operate within its own network segment, with firewall rules controlling inter-segment communication. Orderers talk to each other (Raft cluster port 7053) and to peers (block delivery port 7050). Peers talk to other peers (gossip) and to CouchDB (localhost only). RPC gateways need access to peers and orderers but should be isolated from direct CouchDB access.
# Kubernetes NetworkPolicy for node segmentation
---
# Allow orderer-to-orderer Raft communication
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: orderer-cluster-policy
namespace: fabric-orderers
spec:
podSelector:
matchLabels:
app: orderer
policyTypes:
- Ingress
- Egress
ingress:
# Raft cluster communication (orderer-to-orderer)
- from:
- podSelector:
matchLabels:
app: orderer
ports:
- port: 7053
protocol: TCP
# Block delivery to peers
- from:
- namespaceSelector:
matchLabels:
network: tradelink
podSelector:
matchLabels:
app: peer
ports:
- port: 7050
protocol: TCP
# Gateway transaction submission
- from:
- namespaceSelector:
matchLabels:
network: tradelink
podSelector:
matchLabels:
app: gateway
ports:
- port: 7050
protocol: TCP
# Prometheus scraping
- from:
- namespaceSelector:
matchLabels:
purpose: monitoring
ports:
- port: 9443
protocol: TCP
egress:
- to:
- podSelector:
matchLabels:
app: orderer
ports:
- port: 7053
protocol: TCP
- to:
- namespaceSelector: {}
ports:
- port: 53
protocol: UDP
- port: 53
protocol: TCP
---
# Peer network policy
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: peer-network-policy
namespace: fabric-org1
spec:
podSelector:
matchLabels:
app: peer
policyTypes:
- Ingress
- Egress
ingress:
# Gossip from other peers in same org
- from:
- podSelector:
matchLabels:
app: peer
org: org1
ports:
- port: 7051
protocol: TCP
# Cross-org gossip (anchor peers only)
- from:
- namespaceSelector:
matchLabels:
network: tradelink
podSelector:
matchLabels:
app: peer
ports:
- port: 7051
protocol: TCP
# Gateway queries and endorsement
- from:
- namespaceSelector:
matchLabels:
network: tradelink
podSelector:
matchLabels:
app: gateway
ports:
- port: 7051
protocol: TCP
# Chaincode execution
- from:
- podSelector:
matchLabels:
app: chaincode
ports:
- port: 7052
protocol: TCP
egress:
# Connect to orderers for block delivery
- to:
- namespaceSelector:
matchLabels:
purpose: ordering
ports:
- port: 7050
protocol: TCP
# CouchDB (same pod, localhost)
- to:
- podSelector:
matchLabels:
app: peer
ports:
- port: 5984
protocol: TCP
# DNS
- to:
- namespaceSelector: {}
ports:
- port: 53
protocol: UDP
EOF
# Apply all policies
kubectl apply -f orderer-cluster-policy.yaml
kubectl apply -f peer-network-policy.yaml
# Verify policies are active
kubectl get networkpolicies -A | grep -E "orderer|peer"These NetworkPolicies implement the principle of least privilege at the network layer. Each node type can only communicate with the specific ports and node types it requires. The orderer cluster policy allows Raft communication on port 7053 only between orderer pods, block delivery on port 7050 only from peer and gateway namespaces, and Prometheus scraping from the monitoring namespace. Peer policies restrict CouchDB access to the same pod (localhost), gossip to labeled peer pods, and orderer access only for block delivery.
Capacity Planning and Resource Allocation
Each node type has different resource consumption patterns. Orderers are CPU bound during high transaction throughput. Peers are memory bound due to chaincode execution and CouchDB caching. RPC gateways are network I/O bound with high connection counts. Plan resource allocation based on measured baselines, not assumptions.
# Benchmark script: measure actual resource usage per node type
#!/bin/bash
# capacity-audit.sh - Run on each blockchain host
NODE_TYPE="${1:-peer}"
DURATION=300 # 5 minute sample
echo "=== Capacity Audit: ${NODE_TYPE} ==="
echo "Host: $(hostname)"
echo "Timestamp: $(date -u +%Y-%m-%dT%H:%M:%SZ)"
echo ""
# CPU usage (per core average over sample period)
echo "--- CPU Usage ---"
mpstat -P ALL 10 $((DURATION/10)) | tail -n +4
# Memory usage breakdown
echo ""
echo "--- Memory Usage ---"
free -h
echo ""
cat /proc/meminfo | grep -E "MemTotal|MemFree|Buffers|Cached|SwapTotal|SwapFree"
# Disk I/O for blockchain volumes
echo ""
echo "--- Disk I/O (blockchain volumes) ---"
iostat -xdh /dev/nvme0n1 10 $((DURATION/10)) 2>/dev/null || \
iostat -xdh 10 $((DURATION/10))
# Network connections by port
echo ""
echo "--- Network Connections ---"
ss -s
echo ""
echo "Port breakdown:"
ss -tlnp | grep -E "7050|7051|7052|7053|5984|8545|9443"
# Process-specific resource usage
echo ""
echo "--- Process Resources ---"
case $NODE_TYPE in
orderer)
ps aux | head -1
ps aux | grep "[o]rderer"
echo ""
# Raft WAL directory size
echo "WAL size: $(du -sh /var/hyperledger/production/orderer/etcdraft/wal 2>/dev/null)"
echo "Snap size: $(du -sh /var/hyperledger/production/orderer/etcdraft/snapshot 2>/dev/null)"
echo "Ledger size: $(du -sh /var/hyperledger/production/orderer 2>/dev/null)"
;;
peer)
ps aux | head -1
ps aux | grep -E "[p]eer|[c]ouchdb"
echo ""
echo "Ledger size: $(du -sh /var/hyperledger/production 2>/dev/null)"
echo "CouchDB size: $(du -sh /opt/couchdb/data 2>/dev/null)"
# CouchDB connection count
curl -s http://127.0.0.1:5984/_node/_local/_stats/couchdb/open_databases 2>/dev/null
;;
gateway)
ps aux | head -1
ps aux | grep -E "[g]ateway|[h]aproxy|[e]nvoy"
echo ""
echo "Active gRPC connections:"
ss -tnp | grep -c ":7051"
echo "Active client connections:"
ss -tnp | grep -c ":443"
;;
esac
echo ""
echo "=== Audit Complete ==="Run this audit script on each node type during peak load to establish baselines. For TradeLink Maritime processing 500 transactions per second across the shipping channel, typical resource consumption is: orderers at 40% CPU and 3.2 GB RAM, peers at 65% CPU and 12 GB RAM (with chaincode execution), CouchDB at 30% CPU and 6 GB RAM (heavily cached), and gateway nodes at 15% CPU and 2 GB RAM but with 800+ active gRPC connections. These baselines inform the Kubernetes resource requests and limits in the StatefulSet manifests, ensuring pods are neither starved of resources nor wastefully over provisioned.
Summary
Designing node topology for production blockchain networks requires understanding the distinct responsibilities and scaling characteristics of each node type. Orderer nodes manage consensus and must be distributed carefully in odd numbers across fault domains. Peer nodes handle endorsement and ledger storage, scaling horizontally with query offload patterns. RPC gateways provide the stateless client interface and scale freely behind load balancers. Validator nodes in Ethereum networks combine consensus and execution, requiring dedicated resources and governance based onboarding.
TradeLink Maritime’s deployment demonstrates a proven topology: 5 Raft orderers across 3 data centers, 6 peers with colocated CouchDB instances, 4 gateway nodes behind HAProxy, and comprehensive Kubernetes anti-affinity rules that survive rack, power feed, and full data center failures. Combined with proper network segmentation via NetworkPolicies and role-specific monitoring alerts, this topology delivers the reliability needed for a production shipping consortium processing hundreds of transactions per second.