Part 2 of the AI loan underwriting walkthrough. The real numbers AI lenders quote, the three ways the architecture actually breaks in production, and what a senior underwriter still owns when 88% of loans never touch their desk.
In Part 1, we walked through the architecture a modern AI loan underwriting platform builds over 14 months. Five lanes, 14 components, eight specialist models, one rules engine. The mechanics. What Part 1 did not cover is where the mechanics fail. They do. At every AI loan underwriting platform, the same three failure modes show up in ways that cost real money. Part 2 walks through those failures, the case studies from Upstart and J.P. Morgan that put real numbers on the scale, and the question every Chief Risk Officer keeps asking: what does a senior underwriter actually do when 88% of loans are approved before a human sees them.
Key Takeaways
- The biggest real AI loan underwriting win is cost reduction (₹1,840 to ₹310 per loan in audited cases), not the speed slogan on the billboard.
- Three failure modes hit every AI loan underwriting platform: thin-file rejection, festival-season model drift, and proxy discrimination through correlated features.
- Adverse action notices, generated from SHAP values, are both a regulatory requirement and the cheapest drift-detection system a risk team can run.
- Senior underwriters now handle the 12% of cases the model cannot resolve, and the work that is left is harder than the work they did before.
What Is Inside
The Numbers Everyone Quotes, Sanity-Checked
Every AI loan underwriting deck in circulation over the last two years quotes the same few statistics. The exercise that follows separates which of them are real, which of them are marketing, and which are real but misleading. The image below is the result after running the numbers against audited filings and practitioner reports.
Free to use, share it in your presentations, blogs, or learning materials.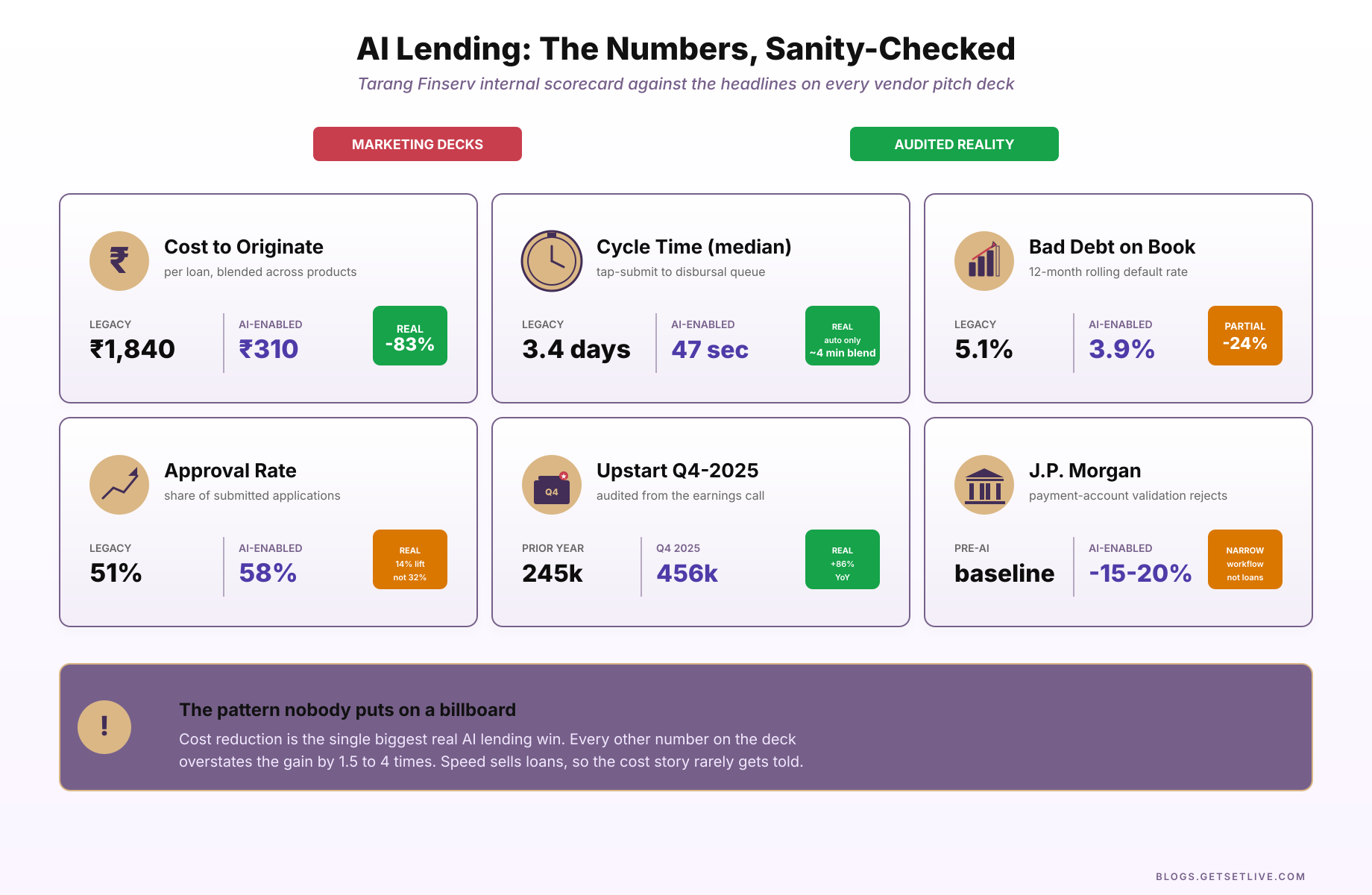
Upstart, the US consumer lending platform, reported in its Q4 2025 earnings that it processed 456,000 loan transactions, an 86% jump year on year, and onboarded over 300,000 new borrowers. That number is real. It comes straight from the earnings call, which means it has been audited.
J.P. Morgan cut payment account validation rejection rates by 15-20% using AI-assisted processing. Also real, also audited, also specifically about one narrow workflow (account validation, not loan approval, which is worth noting because the two are often confused).
The ones worth squinting at: “18-32% increase in approval rates” and “50%+ reduction in bad debt.” These come from vendor case studies, usually for unnamed lenders. They appear in multiple pitch decks. They are plausible for specific customer segments, but they are not audited numbers and they quietly exclude the segments where AI made things worse. Lenders running real AI stacks typically report improvements in the 10-25% range on bad debt, and the real gain is on the cost side, not the top line.
An honest internal scorecard at a mid-size NBFC running a modern AI stack looks like this. Origination cost fell from ₹1,840 per loan to ₹310, an 83% reduction. That is the single biggest real win. Median cycle time fell from 3.4 days to 47 seconds for auto-approved cases, which is 98% faster, but only for 62% of volume, so the blended median is about 4 minutes. Bad debt fell from 5.1% to 3.9%, a 24% reduction, which is meaningful but nowhere near the 50% the glossy decks promise. Approval rate rose from 51% to 58%, a 14% increase, again real but not the 32% the slides claim.
The pattern that keeps repeating: cost reduction is always the biggest win, and it is always the one talked about least, because cost reduction does not sell loans, speed does.
Where AI Lending Actually Breaks
This is the section that gets cut from every vendor pitch. The architecture is impressive. The failure modes are instructive. The diagram below shows the three categories of failure that competent risk teams actively monitor. Each category corresponds to incidents that have cost AI lenders real money over the last two years.
Free to use, share it in your presentations, blogs, or learning materials.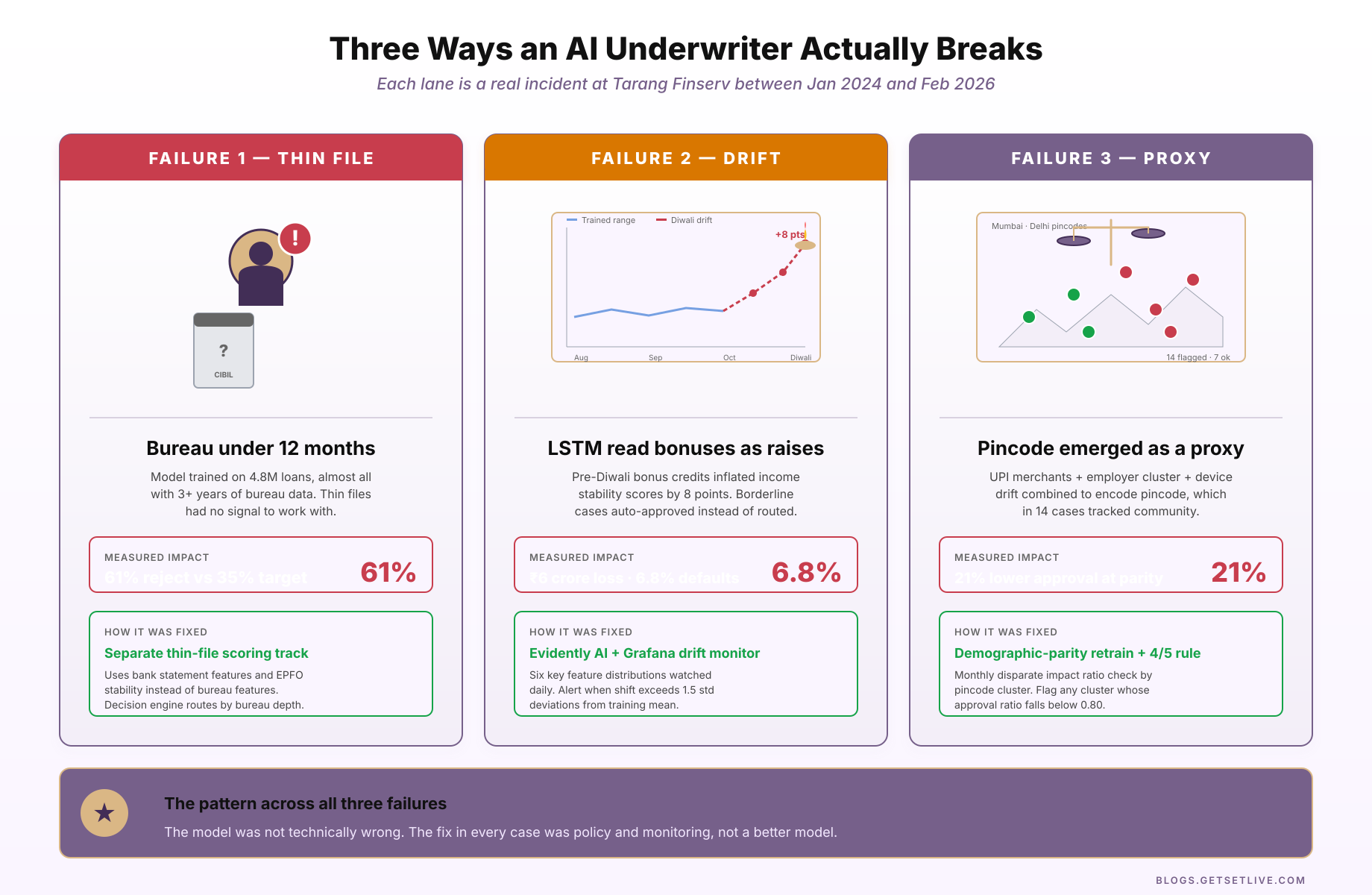
Failure 1: Thin-File Borrowers
A thin-file borrower is someone whose credit bureau history is under 12 months old. In India this includes roughly 85 million adults who are creditworthy but invisible to the bureau. Fresh graduates, gig workers, first-time salaried employees, small-town earners who have never taken a loan. A typical XGBoost model at a mid-size NBFC is trained on 4 to 5 million historical loans, and nearly all of those borrowers carry a credit history of 3+ years. When the model sees an applicant with zero bureau history, it has no signal to work with and defaults to conservative scoring.
Internal audits at one such NBFC in early 2024 found that thin-file applicants were being rejected at 61% against a policy target of 35%. The model was not doing anything wrong mathematically. It was just confident in its uncertainty, and the rules engine was treating that uncertainty as risk. The fix took three months. The team added a separate thin-file scoring track that uses bank statement features and employer stability signals but deliberately ignores bureau features. The two tracks now run in parallel, and the decision engine picks the right one based on bureau history depth.
This is a specific, measurable problem that every AI lender hits. Upstart’s entire early positioning was around this exact issue, and it is why their US originations skew younger than incumbent lenders. If an AI underwriter is quietly rejecting 60% of thin-file applicants, it has a model problem and a policy problem at once, and nobody will see it until someone specifically looks.
Failure 2: Model Drift During Festival Spending
Model drift is the boring, expensive, operational reality that nobody talks about in the AI loan underwriting conference circuit. The model was trained on the last two years of application data. The world in November 2025 does not look like the world the model saw during training. The model does not know this. It scores applicants as if the world is still the training distribution.
A documented drift incident at one Indian NBFC during Diwali 2024 captures the pattern. In the three weeks leading up to Diwali, the model started approving borderline cases at a much higher rate than usual. When the engineering team investigated, they found the LSTM (long short-term memory, a recurrent neural network architecture that learns patterns across time series like monthly salary credits) income stability model was reading pre-Diwali bonus credits as structural salary increases and bumping the stability score by 8 points on average. The rules engine interpreted these inflated stability scores as stronger applicants. Approvals that should have been routed to senior underwriters were auto-approving. Default rate on that cohort came in at 6.8% against a portfolio average of 3.9%. On a one-month disbursal volume of ₹210 crore, the excess default cost the lender about ₹6 crore in loss before they caught it.
The fix was not a better model. The fix was a drift detector built on top of Evidently AI, the open-source ML observability library, with Grafana for visualisation. The team defined six key features and a daily distribution check. The configuration that runs nightly looks roughly like this.
1# Watches six features that move the LSTM income stability score
2# Runs at 02:30 IST on the previous day’s batch, posts to #risk-drift Slack
3report:
4 name: lstm_income_stability_drift
5 schedule: “30 2 * * *”
6 reference_window:
7 source: feature_store_offline
8 window_days: 90 # training distribution baseline
9 current_window:
10 source: feature_store_online
11 window_days: 1 # yesterday’s live applications
12
13features:
14 – salary_credit_avg_3m
15 – salary_credit_date_stddev_days
16 – salary_dip_count_last_6m
17 – upi_outflow_30d
18 – employer_tenure_months
19 – device_location_drift_30d
20
21drift_method: ks # Kolmogorov-Smirnov, p-value below 0.05 = drift
22share_threshold: 0.33 # alert if 2+ of 6 features drift on the same day
23
24alert:
25 channel: slack
26 webhook: ${RISK_DRIFT_SLACK_WEBHOOK}
27 cc_email: cro@example.in
The detector monitors those six feature distributions daily. When the Kolmogorov-Smirnov test fails on two or more features in a single batch, the system pings the risk team and the engineering group reviews whether to retrain or to tighten the threshold manually. This kind of monitoring is the single most underrated piece of infrastructure in a production ML system, and it is the first thing cut when budgets tighten.
Failure 3: Proxy Discrimination via Pincode
This is the failure that keeps compliance teams awake. In late 2024, an internal audit at one AI loan underwriting platform found that applicants from 14 specific pincodes in Mumbai and Delhi were being approved at 21% lower rates than applicants with equivalent credit profiles from adjacent pincodes. Pincode was not an explicit feature in the model. What was a feature was a blend of UPI merchant patterns, employer cluster density, and device location drift over 30 days. These features, taken together, had become a proxy for pincode, which in those 14 cases was a proxy for religious community.
The model had not been told to discriminate. It had learned to. This is the single most dangerous thing about tree-based models on rich feature sets: they find whatever signal correlates with default, and some of those signals are ethically toxic. The risk team pulled those 14 pincodes into a fairness audit, retrained the model with a fairness constraint (demographic parity across pincode clusters, enforced via a reject-inference layer), and now runs a monthly disparate impact ratio check. The CFPB (the US Consumer Financial Protection Bureau, the federal regulator that enforces consumer credit and fair-lending law) and the RBI (the Reserve Bank of India, India’s central banking regulator) have both started asking about disparate impact testing in examinations, and any lender who is not doing this weekly is exposed.
The specific check is: compute approval rate by pincode cluster, divide by the overall approval rate, flag any cluster below 0.80. This is the four-fifths rule that US fair lending law has used since 1978. It is not a machine learning technique. It is a policy check, applied to model outputs. The model does not know about it. The risk team does.
The Adverse Action Problem
When a loan gets declined, the borrower has a right to know why. The US calls this an adverse action notice under ECOA (the Equal Credit Opportunity Act, the 1974 federal law that prohibits credit discrimination on race, religion, sex, age, or marital status) and the FCRA (the Fair Credit Reporting Act, which governs how credit bureau data may be used). The RBI’s Fair Practice Code for NBFCs (non-banking financial companies — lenders licensed by the RBI to extend credit without being deposit-taking banks) requires something similar in India. The rule is: the lender has to give a specific reason, and it has to be actionable. “You were rejected by our AI model” is neither specific nor actionable, and regulators have made it clear it does not count.
This is where the SHAP (Shapley additive explanations, a method that decomposes a model’s prediction into per-feature contributions) values from the XGBoost model earn their keep. When a decision is declined, the pipeline pulls the top 5 SHAP values that drove the score above the rejection threshold and translates them into human language. “Your application showed 7 instances of gambling-related UPI payments in the last 30 days” is actionable. “Your declared income was 38% higher than the salary credit pattern visible in your bank statement” is actionable. “Your AI score was high” is not.
A common operating practice is to keep a shadow log of every adverse action notice the lender sends, and spot-check 50 per week. The reason: if the reason codes stop making sense to a human reviewer, that is often the first sign that the model has drifted into using features in ways nobody expected. Adverse action review is the cheapest, earliest drift detection system available, and it is also a regulatory requirement, so the lender gets it for free.
What a Regulator Examination Actually Looks For
The gap between “the rule says explain your decisions” and what happens when an examiner walks into the office is wider than most lenders prepare for. The examination playbook converges on the same five questions regardless of jurisdiction. Knowing them in advance shifts the conversation from defending the model to walking the examiner through controls already in place.
1. Show me the model card. Both ECOA examiners and RBI inspectors increasingly ask for a written document describing what the model predicts, what features it uses, who owns it, when it was last retrained, and what its known limitations are. A one-page document is fine. A 40-page document looks evasive. The point is that someone takes accountability for the model in writing.
2. Show me a sample of declines with reason codes. The examiner picks ten declined applications at random and asks the team to walk through the reason codes. If three of the ten reason codes read “high AI risk score” without naming a specific feature, that is a finding. Most lenders fail this exercise the first time because their reason-code mapping was built once and never revisited.
3. Show me the disparate impact monitoring evidence. The four-fifths rule check from earlier in this article is what the examiner wants to see — not a one-off audit, but a running monthly report with timestamped outputs. A regulator does not expect zero disparate impact. They expect the lender to know about it before they do.
4. Show me what changes when the model is retrained. Drift between model versions can introduce new bias quietly. Examiners ask for a side-by-side: champion vs challenger, on a held-out test set, with disparate impact metrics for each cohort. Lenders running a shadow-test for two weeks before promotion have this artefact already. Lenders who promote on accuracy alone do not.
5. Show me the override log. When a senior underwriter overrules the model, what does the audit trail look like? The override log is one of the most under-built artefacts at AI lenders. RBI inspectors specifically ask: who overrode, on what date, with what reason, and what was the outcome 90 days later. A lender that cannot produce this log on the spot is exposed.
None of these requests are about the math. They are about the lender’s operational rigour around the math. The model can be wrong as long as the lender knows the model can be wrong, has a process to detect it, and has a written paper trail of what the team did about it.
What the Senior Underwriter Does Now
A common assumption in the AI loan underwriting discourse is that senior underwriters lose their jobs. The opposite is observed in practice. Their queue gets longer and the cases get harder. The diagram below maps how the human-model partnership actually splits responsibility inside a mature AI lender.
Free to use, share it in your presentations, blogs, or learning materials.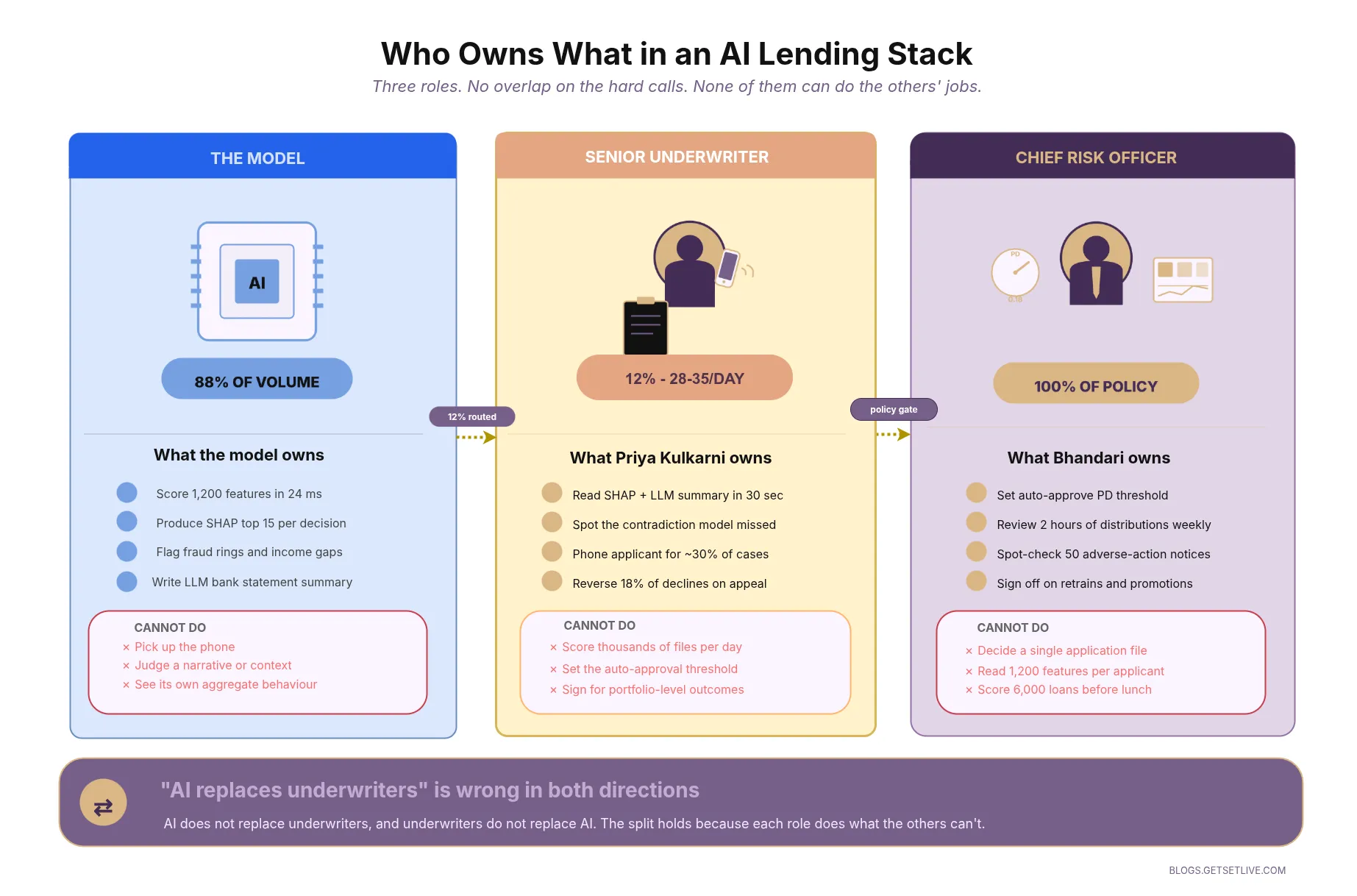
A senior underwriter at an AI lender handles roughly 28-35 cases a day. The cases they see are the 12% that the rules engine routes to human review. Every one of them is ambiguous. Either the risk score is in the middle band, or the applicant’s profile has a contradiction the model cannot resolve, or the declared amount is above the auto-approval ceiling. The underwriter’s screen shows the applicant’s summary (the paragraph written by an LLM (large language model, the same family that powers chat assistants) running locally on a Llama-3 class checkpoint), the top 15 SHAP values from XGBoost, the graph model flag, and the raw bank statement. They spend 8 to 14 minutes per case.
What the senior underwriter does in those 8 minutes is the interesting part. They look for the thing the model cannot see. A narrative. A story. An applicant has been steady for four years, the salary credits look right, and there is one weird ₹18,000 debit labelled SWIGGY that makes no sense at this income level. Is the applicant running a dark kitchen on the side? A phone call. Senior underwriters at AI lenders pick up the phone for about 30% of their cases. The model cannot do that. The model will never do that. That phone call is where a lot of the real risk assessment happens.
The Chief Risk Officer does something different. The CRO does not look at individual cases anymore. The CRO looks at distributions. Every Monday morning, two hours go into reviewing the week’s approvals, declines, and defaults, sliced by pincode, age band, employer type, and loan size. The CRO is looking for patterns the model cannot see because it cannot see its own aggregate behaviour. When the CRO finds a pattern, the response is either to tighten a threshold or commission a model retrain. The CRO’s decisions are the ones that actually shape the lender’s risk posture.
This is the split that every serious AI lender ends up at. The model does the tabular, repeatable, fast work. The senior underwriter does the narrative, judgement-heavy, exception work. The CRO does the aggregate, policy, accountability work. None of the three can do the others’ jobs. The marketing slogan “AI replaces underwriters” is wrong in both directions, because AI does not replace them and underwriters do not replace AI.
What This Means If You Are a Borrower
A few practical observations for anyone who will actually apply for an AI-underwritten loan, which is now roughly 70% of consumer personal loans in India.
First, the system is faster, not fairer. Faster means the application gets a decision in 47 seconds. Fairer would mean the decision is consistently good across borrower types. The honest answer on fairness is: mostly yes, sometimes no, and the “sometimes no” cases are exactly the edge cases most likely to involve first-time borrowers, small-town applicants, or anyone whose financial profile does not look like a metro software engineer’s.
Second, every borrower has a right to know why they were declined. If the decline arrives with no specific reason, or with a reason that is not actionable, that decline can be pushed back on. Every NBFC in India is now required to furnish a specific reason under RBI’s Fair Practice Code. Ask in writing. Keep the response. It is worth something if the borrower appeals.
Third, the thing that moves the score most is not what most borrowers think. CIBIL is one of 1,200 features in a modern AI underwriter. The features that actually move the score are things like: consistency of salary credits, absence of gambling merchant patterns, EPFO employer tenure, and stability of UPI counterparty concentration. To improve odds: stop gambling on Dream11 two months before applying, keep the same employer for at least 18 months, and have salary credited on the same date of every month.
Fourth, if the model got it wrong, ask for human review. Every responsible lender has a manual review path. Use it. Senior underwriters at AI lenders reverse roughly 18% of decline decisions when applicants push back and provide additional context. The model gets things wrong. That is not a secret. The system is designed to let humans correct it. Not enough borrowers know to ask.
Anti-Patterns: Things Vendors Sell That Don’t Actually Work
The same vendor pitch decks that overstate gains also push specific architectures that look impressive in a demo and fall over in production. Five anti-patterns recur often enough to be worth naming.
1. The single foundation model that scores everything. The pitch: a 70B-parameter LLM ingests the application, the bank statement, and the bureau record, and outputs a probability of default. The reality: large language models are bad at tabular reasoning, slow, expensive to serve at the millisecond budget loan applications need, and impossible to defend to an examiner. Every production AI lender uses an LLM for one narrow job (summary for human review) and never lets it touch the decision.
2. Synthetic data from a GAN for fairness training. The pitch: generative adversarial networks produce thin-file applicant data that lets the model learn on a balanced cohort. The reality: synthetic borrowers have synthetic outcomes. The model trains on fiction and then encounters real applicants whose patterns the GAN never produced. Better fixes exist (reject-inference layers, sample reweighting, separate scoring tracks) and they survive contact with regulators.
3. “Explainable AI” dashboards that don’t satisfy regulators. The pitch: a colourful dashboard shows feature importance bars and a SHAP waterfall. The reality: examiners ask for actionable per-applicant reason codes, not aggregate feature importance. A dashboard built for the engineering team is not the same as a reason-code generator built for the borrower-notice pipeline. Both are needed. Most vendors ship one and call it the other.
4. Fairness fixes applied at inference time. The pitch: a post-processing layer rebalances the model output to enforce demographic parity. The reality: this is detectable by a halfway competent auditor and reads as “we knew the model was biased and patched the symptom.” Fixing bias at training time (constrained optimisation, reweighted samples, removed proxy features) is harder but defensible. Fixing bias at inference time satisfies no one.
5. “AI-powered” KYC that hides a manual review queue. The pitch: automated identity verification in seconds. The reality: many vendors route ambiguous cases to a human review queue offshore and call the latency “model processing.” This is fine as a business choice. It is not fine when the vendor charges AI prices for it and the lender finds out only after onboarding. Always ask for the fallback rate.
The pattern across all five: the technology described in the pitch does exist, just not in the role the pitch claims. A buyer who knows the boundary between what the model is doing and what is glued around it will not get sold the wrong thing.
What I’m Writing Next
Next up on this blog, I’m taking the same lens into banking, specifically how AI sits inside a modern fraud detection and AML pipeline. The banking stack adds streaming infrastructure, graph neural networks for mule-ring detection, and the unpleasant arithmetic of false-positive economics at scale. Different domain, same questions: which parts are real engineering, which parts are marketing, and where does this break in production. Look out for it on the blog over the next couple of weeks.
Related Reading
References
- PYMNTS, Earnings Show AI Lending Platforms Scaling Originations, 2026
- Reserve Bank of India, Fair Practice Code for NBFCs, latest amendment
- Consumer Financial Protection Bureau, Regulation B (ECOA) adverse action guidance
- Bonadio, Practical Applications of AI in Financial Institutions: Lending, 2026
- Canopy Servicing, AI in Lending: How It Is Used Today, 2026
Frequently Asked Questions
Under RBI’s Fair Practice Code for NBFCs and the US ECOA framework, lenders are required to provide specific, actionable reasons for declines. If you got a vague rejection, ask in writing for the specific features or variables that drove the decision. Responsible lenders translate SHAP values from their models into human-readable reason codes.
Most AI lenders run a separate scoring track for thin-file borrowers that uses bank statement features, employer stability signals, and UPI payment patterns instead of bureau features. Without this second track, thin-file applicants often get rejected at much higher rates than their actual risk justifies.
Yes, and it happens. Tree-based models trained on rich feature sets can quietly learn proxy features that correlate with pincode, which can in turn correlate with community. The only defence is monthly disparate impact testing (the four-fifths rule) applied to model outputs, not just to the model inputs.
Model drift is when the real-world distribution of applications moves away from the distribution the model was trained on. Festival spending patterns, post-pandemic income changes, and seasonal employment shifts all cause drift. Without a drift monitor (Evidently AI, Grafana, or similar) watching key feature distributions daily, drift can cause default spikes before anyone notices.
Yes, and the job has changed. Senior underwriters now handle the 10-15% of cases that are ambiguous, contradictory, or above the auto-approval ceiling. They pick up the phone, investigate narratives, and correct model errors on appeal. Chief Risk Officers set the thresholds and monitor aggregate behaviour, which the model cannot see.
Yes. The logistic regression baseline running alongside XGBoost is fully explainable, and SHAP values translate the gradient-boosted score into per-feature reasons that satisfy RBI and CFPB examinations.
Most AI lenders retrain monthly on a rolling window, then shadow-test the new model against production for two weeks before promotion.