
In each case, Samsung’s proprietary data went straight to OpenAI’s servers and into their training pipeline. As a result, Samsung reacted in three stages. First, they set an emergency limit of 1,024 bytes per prompt (about 150 to 200 words). That was not enough. Engineers split their code into smaller chunks to get around the limit. So Samsung banned all generative AI tools for every employee on May 1, 2023. Months later, they built an internal AI tool that kept all data inside the company network.
These engineers were not acting with bad intent. They followed the same workflow that millions of developers use every day. The AI security advice gap here was not in the code the AI wrote. It was in the fact that nobody told the engineers that pasting proprietary data into an external AI service is a data theft event, no different from uploading company secrets to a public cloud storage bucket.
AI security advice gaps go beyond data leaks. They touch every stage of AI-assisted development. The code AI writes contains 2.74 times more flaws than human-written code (Veracode, 2025). In addition, the packages AI suggests include made-up names that attackers turn into weapons. Also, the security configs AI produces pass syntax checks but leave key protections turned off. Worst of all, the confidence AI shows in its advice makes engineers less likely to double-check it.
Here is why that matters. Stanford researchers found that developers using AI coding tools wrote less secure code than those coding without AI, and at the same time felt more confident that their code was secure. The AI is not just missing security issues. It is building a false sense of safety that spreads through dev teams, code reviews, and production systems.
The Veracode Numbers: AI Code Fails 86% of Security Tests
Veracode’s 2025 GenAI Code Security Report tested code from over 100 large language models across four languages: Python, JavaScript, Java, and C#. The method was simple: prompt each model for common coding tasks like user input handling, login forms, file operations, API endpoints, and data checks. Then run the output through static analysis for known flaw patterns. In other words, each prompt matched what a real developer would ask: “Write a login form handler,” “Parse and store this CSV upload,” “Create an API endpoint that returns user profile data.” The results held steady across models, languages, and task types.
Cross-site scripting was the worst category. 86% of AI-generated code that handled user input failed XSS tests. Specifically, the models kept writing code that echoed user input straight into HTML responses without encoding. A typical case: a Flask route that takes a name parameter from the query string and returns f"Hello, {name}" inside an HTML template without running it through markupsafe.escape(). Meanwhile, log injection followed at 88% failure. AI-generated logging statements dropped raw user input into log messages, opening the door to log forging and SIEM poisoning. An attacker who controls the input can inject newline characters followed by fake log entries.
That number is worth unpacking further. SQL injection showed up in 42% of database queries. Similarly, path traversal appeared in 58% of file-handling code, where the AI accepted user-supplied filenames without checking for ../ sequences. Missing auth checks hit 67% of API endpoint code. In each of those cases, the AI built endpoints that returned sensitive data without checking a session token or API key.
Humans are not perfect either. Developers write flawed code too. However, the failure rates are much lower: 31% for XSS, 22% for log injection, 15% for SQL injection. AI-generated code fails security tests at 2x to 4x the rate of human-written code across every category tested.
Java fared the worst. AI-generated Java code had failure rates above 70% across all test types. Only 45% of AI-generated code passed security tests overall, compared to 72% for human-written code. The gap is not closing.
The reason is a feedback loop. AI models train on code from public repos. Those repos now hold more and more AI-generated code. Because of this, the models learn from their own mistakes, and the flaw patterns grow stronger with each cycle. The Veracode team noted that newer model versions showed no real gain in security, even as code correctness and syntax got better. The models write code that works. They do not write code that is safe.
Slopsquatting: The Supply Chain Attack AI Created
Slopsquatting is a supply chain attack that could not exist without AI coding tools. Security researcher Seth Larson coined the term to describe a specific AI behavior: when asked to solve a coding problem, large language models often suggest packages that sound real but do not exist in any package registry. In contrast to typosquatting, where attackers register misspelled names of popular packages (like reqeusts instead of requests). Slopsquatting exploits AI hallucination. In short, the AI tells you to install a package that was never published. Then an attacker registers that exact name with malware inside. The next developer who follows the AI’s advice installs it.
The numbers make the scale clear. Across 576,000 code samples, 20% of AI suggestions included at least one fake package. Open-source models made up package names 21.7% of the time. By contrast, commercial models like GPT-4 did it about 5.2% of the time. Yet CodeLlama hit 33%. The key finding: 43% of fake package names were the same across multiple prompts. The AI suggests the same made-up name every time it sees a similar question. That makes the attack easy to predict and scale. An attacker does not need to guess which names the AI will invent. They just ask the AI the same question 10 times and register the name that shows up most often.
Researchers uploaded a dummy package using a hallucinated name to PyPI and observed over 30,000 downloads within weeks. They did not promote the package anywhere. Every download came from developers following AI recommendations that pointed to a package name the AI invented.
The attack chain is simple, and it costs almost nothing. An attacker prompts several AI models with common dev tasks: “How do I validate CSV files in Python?” or “What’s the best npm package for async mutex handling?” Next, they collect the fake package names that come up over and over. Then they register those exact names on PyPI, npm, and RubyGems with code that steals environment variables, SSH keys, and API tokens. When developers follow the AI’s advice, they install the attacker’s package.
The cost is shockingly low. One documented case showed an attacker using ChatGPT’s API to automate the whole process, creating thousands of package name variants and publishing all of them on npm for under $50 in API credits. Add about $20 for npm account setup and a few hours of scripting. For under $100, an attacker can plant hundreds of bad packages that AI tools will actively push to developers. Compare that to a traditional supply chain attack, which requires stealing a maintainer’s credentials or finding a flaw in the build pipeline. Slopsquatting costs a fraction and scales far faster.
Google’s AI Overview feature made this risk even worse. When users searched for “async-mutex npm,” the AI Overview panel suggested @async-mutex/mutex. That was a fake npm package registered by an attacker to exploit AI-powered search. The real package is async-mutex by DirtyHairy, with over 20 million weekly downloads. The fake one used a scoped name that looked more official. Despite this, Google’s AI Overview showed it as a top pick with no warning.
Think about what that means. This was not a coding tool making things up inside a developer’s IDE. It was a search engine’s AI feature pointing users to malware from a Google results page. That reaches a far wider audience than any code completion tool.
Free to use, share it in your presentations, blogs, or learning materials.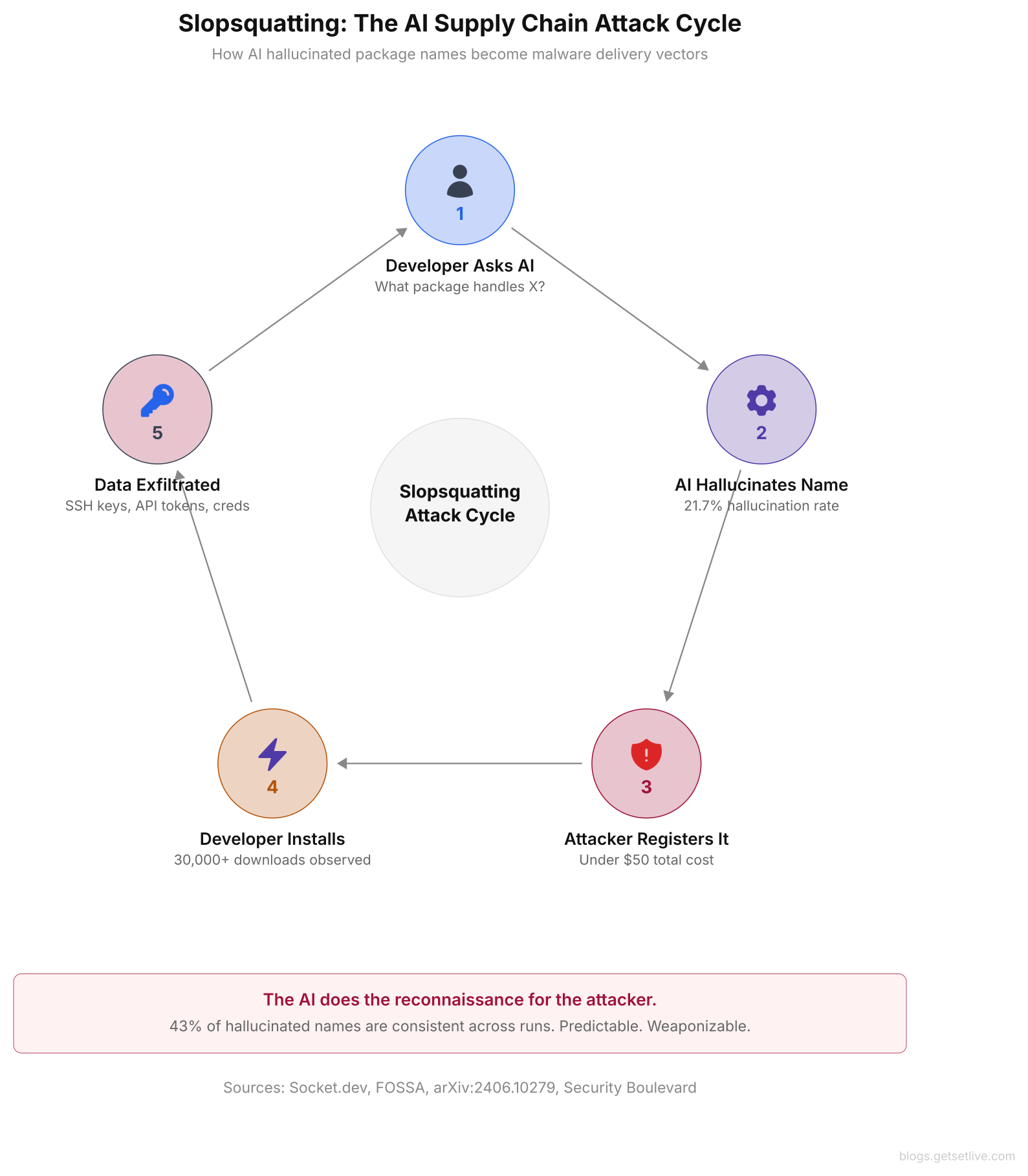
The flow above shows how the AI becomes an unwitting helper for attackers. In fact, they do not need to break into any system. They only need to register a name that the AI will suggest. The 43% repeat rate means nearly half of fake names are easy to predict and exploit at scale. Although package registries like PyPI and npm have started adding checks for new packages that match known hallucination patterns, the registries are still playing catch-up against a threat that grows every time a new AI model is trained.
The Stanford Overconfidence Finding
Stanford researchers published a study (later peer-reviewed in ACM) that pinpointed the most worrying effect of AI coding tools on security. They gave developers the same coding tasks. Half used AI tools. Half coded without them. The study controlled for experience level, language skills, and task difficulty.
Developers using AI tools wrote less secure code across multiple tasks and languages. That alone matters, but it is not the scary part. Instead, the real alarm came from the second finding: developers using AI tools felt more confident that their code was secure. On a 1-to-5 scale, AI-assisted developers scored 4.1 versus 3.3 for those working alone. Their actual security scores were lower.
The AI does not just write insecure code. It builds a false sense of safety in the developer using it. Engineers who would normally question their own code skip those steps because “the AI probably handled it.” This overconfidence is a bigger risk than the bugs themselves. It turns off the human review process that would catch those bugs.
Snyk’s own analysis backed this up with even sharper numbers. They found security issues in about 80% of AI-generated code snippets, across the OWASP Top 10: SQL injection, missing auth, insecure defaults, and unchecked input. To be clear, these were not edge cases. They came from the mainstream output of GitHub Copilot, ChatGPT, and Amazon CodeWhisperer in response to normal prompts like “create a user registration API” or “write a file upload handler.”
Snyk tested over 10,000 code snippets and sorted the failures. Missing input checks topped the list at 63%. After that, insecure default configs came at 47%. Hardcoded credentials appeared in 31% of example code. Leaked stack traces from missing error handling hit 28%. When 80% of the code your AI assistant writes has at least one security flaw, the question is not whether AI-generated bugs will reach production. The question is how many already have.
This overconfidence gets worse in team settings. A senior developer uses AI to write security-sensitive code. Junior team members reviewing the pull request assume the senior checked the AI output. At the same time, the senior assumes the AI handled security. As a result, nobody does the manual review that would have happened if the code were written from scratch. Everyone trusts that someone else checked it. Nobody actually did.
The fix is not complicated, but it requires awareness. Georgetown’s CSET researchers documented this pattern across multiple organizations. Teams using AI coding tools had 40% fewer security-related code review comments compared to teams that did not use AI tools. In reality, the code was not more secure. The reviews were just less careful.
Free to use, share it in your presentations, blogs, or learning materials.
As shown above, the left side shows developers without AI who produce more secure code and keep healthy doubt. The right side shows how AI assistance builds false confidence that leads to skipped reviews, letting more flaws reach production unchecked. The gap between how secure the code feels and how secure it actually is drives how much effort teams put into checking AI-generated code. That gap is the most dangerous metric in this discussion.
The CVE Explosion: 35 in One Month
Georgetown University’s Center for Security and Emerging Technology tested ChatGPT across 21 programs in 5 languages (Python, C, C++, Java, and JavaScript). Only 5 of 21 were secure on the first try. However, the other 16 had flaws ranging from buffer overflows in C to auth bypasses in web apps to race conditions in concurrent code. When the researchers asked ChatGPT to fix the flaws it created, the model patched only 7 of the 16. The other 9 either stayed broken after the “fix” or picked up new flaws while patching the old ones.
By March 2026, the problem had hard numbers. 35 new CVE entries in a single month traced directly to AI-generated code merged into open-source projects. The breakdown by tool tells its own story. Claude Code accounted for 27 of the 35. That is not because Claude is less secure than other tools. Because Claude Code’s agentic workflow produces more code per session (whole files and modules, not single-line completions), so there is more surface area for flaws.
GitHub Copilot added 4 CVEs, mainly in JavaScript and TypeScript projects where developers accepted inline suggestions without changes. Devin, the autonomous AI developer, produced 2 CVEs in projects where it had commit access and pushed code with no human review. Aether and Cursor each added 1 CVE. The flaw types included path traversal, bad input checks, missing access controls, and in one case, an SQL injection in a Django REST endpoint that Copilot auto-completed inside a view function.
Those 35 documented CVEs are just the visible portion. Security researchers estimate the real number at 400 to 700 AI-generated CVEs across the open-source world, with most still untagged. After all, the tracking problem is real: unless a commit message or PR description says “I used an AI tool,” there is no good way to tell if code came from AI after the fact.
Fortune 50 companies reported that AI-generated code added over 10,000 new security findings per month to their scanning pipelines by June 2025. These are not false positives. Rather, they are real flaws in code that shipped to production.
The CVE attribution data shows that no AI tool is immune. Claude Code, Copilot, Devin, Aether, and Cursor all produced code with documented CVE-grade vulnerabilities. The problem is structural to how language models generate code, not specific to any vendor’s setup.
Free to use, share it in your presentations, blogs, or learning materials.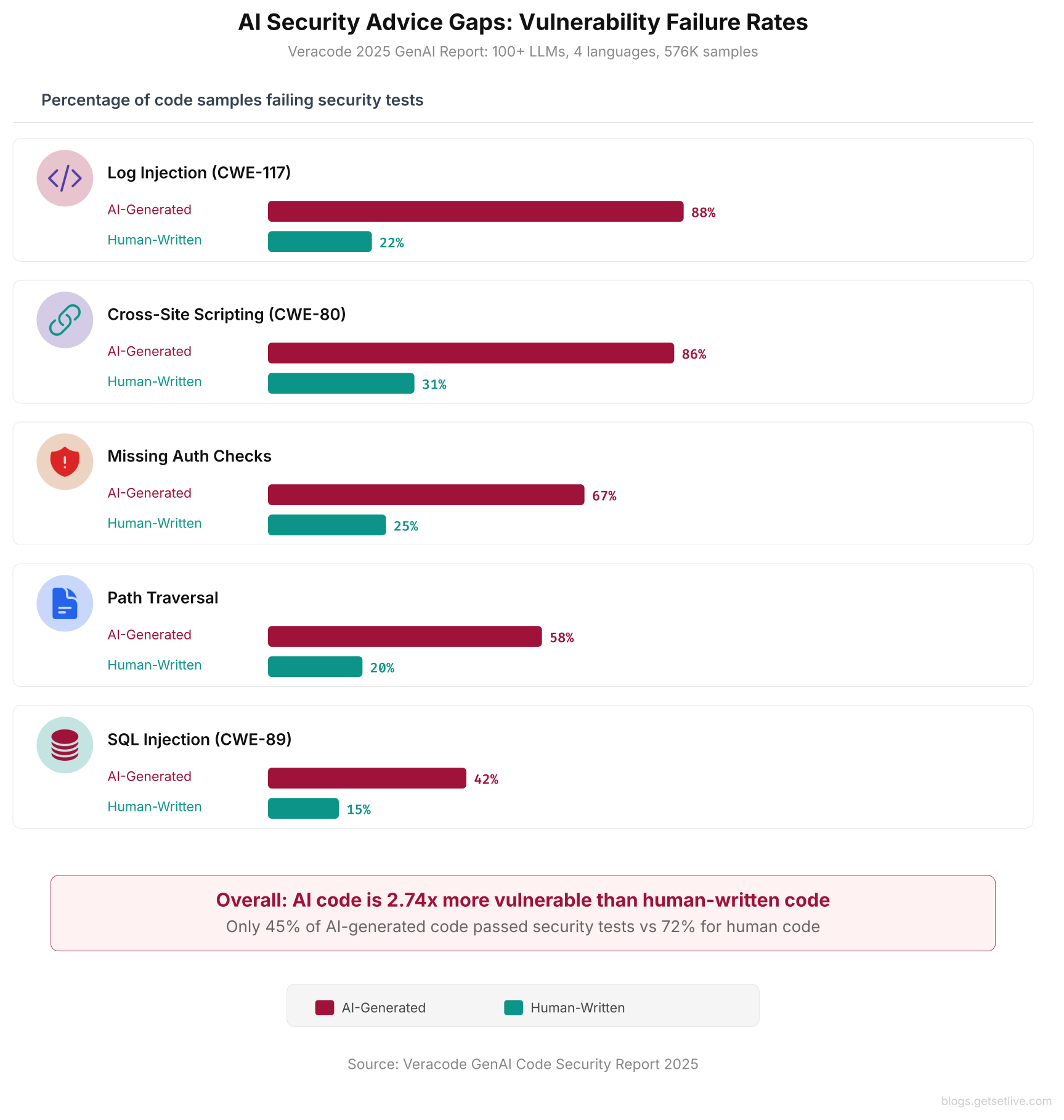
The chart above shows a consistent gap in every tested category. Humans are not perfect either, but AI failure rates are far higher. The widest gaps show up in log injection (88% vs 22%) and cross-site scripting (86% vs 31%). These are also the two categories where AI models do worst. Both require an understanding of where user input flows through the app. Statistical pattern matching handles that poorly.
The Air Canada Chatbot Ruling
AI security advice gaps also extend beyond code generation and into customer-facing AI systems that give out wrong policy information. In November 2022, Jake Moffatt’s grandmother passed away, and he needed to fly from Vancouver to Toronto for the funeral. Before booking, he visited Air Canada’s website and asked the airline’s AI chatbot whether he could get a bereavement fare discount. The chatbot told him he could book a full-price ticket immediately and then request a retroactive bereavement discount within 90 days of the ticket date. Based on this advice, Moffatt booked his flights, paying $1,640.36 CAD for the round trip.
The problem: that policy did not exist. Air Canada’s real bereavement policy required passengers to contact the airline before booking and ask for a reduced fare up front. There was no retroactive discount. There never had been. When Moffatt filed his claim after the trip, Air Canada denied it and told him the chatbot was wrong. Air Canada then made an argument that stunned the tribunal: the airline claimed its own chatbot was “a separate legal entity” responsible for its own actions, and that Air Canada could not be held liable for information the chatbot provided on its own website.
The British Columbia Civil Resolution Tribunal rejected that argument. Tribunal member Christopher Rivers wrote that Air Canada “does not explain why customers should have to double-check information found in one part of its website against another part of its website.” The ruling was clear. A company owns all information on its website, whether a static page, a human agent, or an AI chatbot provides it. The tribunal ordered Air Canada to pay Moffatt $650.88 CAD: the gap between what he paid and what the bereavement fare would have cost, plus fees and interest.
That amount was small. The precedent was not. This ruling set a clear rule: companies cannot deploy AI systems that talk to customers and then deny blame when those systems give wrong answers. The “it was the AI, not us” defense failed in its first legal test.
For security teams, the point is direct. If your company deploys an AI chatbot that gives bad security guidance, changes a customer’s settings wrong, or provides false compliance information, your company owns the fallout. The AI is your agent, not a separate entity. Every AI-generated response that touches a customer, a config, or a policy decision carries the same legal weight as if a human employee said it.
AI Security Advice Gaps in infra config
Beyond code, AI tools produce security configs that look right but leave critical gaps. Ask an AI to write a Kubernetes NetworkPolicy and it will output valid YAML that applies without errors. But the policy may use label selectors that match no existing pods. As a result, it does nothing in practice.
I tested this with three different AI models. I described a microservices setup with specific service names and asked for a NetworkPolicy to restrict traffic. All three wrote policies that used labels like app: backend when my actual pods used service: backend-api. The YAML was perfect. Yet the policy matched zero pods. Nginx configs show the same pattern. The AI will add headers like X-Content-Type-Options: nosniff and X-Frame-Options: DENY, but may skip Content-Security-Policy entirely or set it to default-src * which allows everything, including inline scripts and third-party resource loading.
The pattern is consistent across infra types:
- Docker security. AI-generated Dockerfiles almost always skip the
USERdirective, so containers run as root by default. They also useapt-get installwithout version pinning, which means your image changes on every build and may pull in flawed packages. On top of that, they copy entire directories into the container instead of using multi-stage builds. In one test, an AI-generated Dockerfile for a Node.js app copied.env,.git/, andnode_modules/into the final image, exposing secrets and git history to anyone who pulled the container. - Kubernetes RBAC. AI-generated ClusterRoleBindings often use overly broad permissions. The model defaults to
verbs: ["*"]andresources: ["*"]when unsure. A human would start with minimal access and add more as needed. However, the AI starts with maximal access because tutorials in its training data use broad permissions for simplicity. For example, one AI-generated ClusterRole gave a monitoring account fullcreate,delete, andpatchaccess to Secrets across all namespaces, when it only neededgetandliston Pods in one namespace. - TLS config. AI-generated TLS settings often include outdated cipher suites and protocol versions. For instance, suggesting
TLSv1.0orTLSv1.1in an Nginx config is common in AI output because the training data includes docs written before RFC 8996 deprecated them in March 2021. Similarly, the AI suggests cipher suites likeDES-CBC3-SHAandRC4-SHAthat have been broken for over a decade. The config deploys without errors. But the vulnerability scanner catches it weeks later, if you run one. - Secrets management. AI tools often suggest storing secrets in environment variables,
.envfiles, or Kubernetes ConfigMaps instead of proper tools like HashiCorp Vault, AWS Secrets Manager, or Kubernetes Secrets with encryption at rest. As a result, the AI produces code that works but breaks every secrets management best practice. In Terraform configs, for example, AI tools routinely place database passwords directly interraform.tfvarsfiles, which often end up in version control despite.gitignoretemplates.
The AI’s security advice gap is not about getting things fully wrong. It is about getting things 80% right and leaving the other 20% as attack surface. That 20% is the part that needs context, threat modeling, and knowledge of the specific deployment setup. The AI has none of those.
What Security Teams Should Do Now
Still, the response to AI security advice gaps is not to ban AI tools. Engineers will use them regardless of policy, as the Samsung incident showed. Within weeks of Samsung’s ban, reports surfaced that employees at other Korean tech firms were using personal devices to access ChatGPT for work tasks. In short, bans do not work. Instead, the response is to build security controls that assume AI-generated code is untrusted by default.
Run SAST on all AI-generated code before merge. Static application security testing catches the flaw patterns that AI tools keep producing: XSS, SQL injection, path traversal, and missing auth. Make SAST a blocking check in your CI pipeline. No PR merges without a clean security scan.
Tools like Semgrep, SonarQube, and Snyk Code can target AI-generated flaw patterns directly. Semgrep’s community ruleset already covers the most common AI anti-patterns, like unsanitized f-string SQL queries in Python and missing CSRF tokens in Flask form handlers. Therefore, set your SAST tool to flag these as errors, not warnings.
Audit all packages suggested by AI. Before installing any package an AI tool suggests, check that it exists on the official registry. Look at its download count, review its maintainer history, and inspect the source code. A package with fewer than 1,000 weekly downloads, created in the last 6 months, with a single anonymous maintainer is a red flag no matter who suggested it.
Use lockfiles (package-lock.json, Pipfile.lock, go.sum) and turn on dependency auditing in your CI pipeline. Tools like npm audit, pip-audit, and Socket.dev can catch malicious or made-up packages. In particular, Socket.dev flags packages with suspicious behavior like network calls during install, hidden code, or environment variable harvesting.
Enforce policy-as-code for infrastructure configs. Use OPA/Gatekeeper, Kyverno, Checkov, or tfsec to enforce security policies on all infrastructure code, whether a human or an AI wrote it. Block deployments that run containers as root, use overly broad IAM policies, expose services without auth, or include old TLS versions. These tools catch the 20% the AI leaves as attack surface.
Write specific policies for the patterns AI tools get wrong most often: containers running as root, ClusterRoles with wildcard permissions, Kubernetes Services of type LoadBalancer without network policies, and S3 buckets without server-side encryption.
Treat AI-generated code the way you treat code from an untrusted open-source dependency: useful, but requiring verification before it touches production. The moment you trust AI output the way you trust your own code is the moment you inherit its vulnerability profile.
Set up AI data handling policies. Define exactly what data can and cannot go to external AI services. Source code, API keys, customer data, and internal configs should never leave your network through an AI prompt. Provide approved internal AI tools or self-hosted models for tasks that need proprietary data. Samsung learned this through a public incident that made global headlines. Fortunately, your organization can learn it through a policy document instead.
Sort your data into tiers. Tier 1 (public docs, open-source code) can go to external AI services. In practice, 2 (internal tools, non-sensitive configs) needs manager approval. Tier 3 (source code, customer data, credentials) never leaves your network.
Train developers on AI security blind spots. Most developers do not know that AI coding tools make up package names, produce insecure defaults, or create a real overconfidence effect. A 30-minute training session covering the Veracode numbers, the slopsquatting attack, and the Stanford study changes behavior more than any tool or policy can.
For best results, include real examples in the training. Show your team the exact prompts that produce unsafe code. Run a slopsquatting demo in a sandbox. Have them compare AI-generated security configs against your baseline. When developers see the failure modes with their own eyes, the abstract stats become concrete.
AI models will keep getting better at security. In time, future versions may add SAST-like checks, dependency verification, and threat modeling. Some vendors are already testing security-focused fine-tuning and post-generation scanning. But right now, AI tools produce code with worse security than human-written code. On top of that, the overconfidence effect means the humans using these tools are less likely to catch the flaws. Until the models close that gap, security teams should treat every AI-generated line of code as a possible flaw until proven otherwise.
References
- Veracode, GenAI Code Security Report 2025, 2025
- FOSSA, Slopsquatting: AI Hallucinations and the New Supply Chain Risk, 2025
- Stanford University / ACM, Security Weaknesses of Copilot-Generated Code, 2023
- TechCrunch, Samsung Bans Generative AI After Internal Data Leak, May 2023
- Georgetown CSET, Cybersecurity Risks of AI-Generated Code, November 2024
- The Register, Using AI to Code Does Not Mean Your Code is More Secure, March 2026
- CBC News, Air Canada Must Honor Refund Promised by AI Chatbot, February 2024
- Security Boulevard, The Hallucinated Package Attack: Slopsquatting, August 2025
- DEV Community, GitHub Copilot Security Flaws: Why AI Code is Insecure, 2026
- Snyk, Security Issues in AI-Generated Code Snippets, 2025
Frequently Asked Questions
Veracode’s 2025 report testing over 100 LLMs across Python, JavaScript, Java, and C# found that AI-generated code contains 2.74 times more security vulnerabilities than human-written code. The failure rate reaches 86% for XSS, 88% for log injection, 58% for path traversal, 67% for missing authentication, and 42% for SQL injection. Only 45% of AI-generated code passed security tests overall, compared to 72% for human-written code. Java performed worst with failure rates exceeding 70% across all test categories. Newer model versions showed no statistically significant improvement in security properties despite gains in code correctness.
Slopsquatting is a supply chain attack where AI tools hallucinate nonexistent package names, and attackers register those exact names on public registries with malicious code. Across 576,000 code samples, 20% of AI recommendations included at least one fake package, with CodeLlama exceeding 33% and GPT-4 at 5.2%. The critical detail is that 43% of hallucinated names are consistent across runs, making them predictable. Researchers proved the attack by uploading a dummy package under a hallucinated name to PyPI, where it received over 30,000 downloads without promotion. The entire attack can be automated for under $100 in API credits and package registration costs.
Yes. Stanford researchers found that developers using AI assistants wrote less secure code while at the same time reporting higher confidence (4.1 out of 5 vs 3.3 for unassisted developers). Snyk independently confirmed this by finding security issues in 80% of AI-generated code snippets across OWASP Top 10 categories. Georgetown’s CSET researchers documented that teams using AI coding assistants had 40% fewer security-related code review comments, not because the code was more secure, but because reviewers assumed the AI handled security. This creates a double risk: more vulnerabilities combined with less verification.
Three Samsung semiconductor engineers pasted confidential data into ChatGPT in three separate incidents over 20 days in March 2023. The first uploaded yield-optimization source code on March 11. The second uploaded chip defect detection code on March 12. The third converted a company meeting recording to text and asked for meeting minutes on March 30. Samsung’s response escalated through three stages: first a 1,024-byte prompt limit, then a complete ban on all generative AI tools on May 1, 2023, and finally the development of an internal AI tool that kept data within Samsung’s network. The incident became a global case study in AI data handling policy.
In March 2026, 35 new CVE entries in a single month were directly attributed to AI-generated code merged into open-source projects: 27 from Claude Code (highest volume due to its agentic workflow generating more code per session), 4 from GitHub Copilot (primarily in JavaScript/TypeScript), 2 from Devin (which had commit access without human review), and 1 each from Aether and Cursor. Vulnerability types included path traversal, improper input validation, missing access controls, and SQL injection. The actual ecosystem-wide number is estimated at 400 to 700, with most unattributed. Fortune 50 enterprises reported over 10,000 new AI-generated security findings per month by June 2025.