A walk through the architecture of an AI loan underwriting system at a mid-size NBFC that rebuilt its risk desk from scratch, with a look at what the models really do and what still sits on a human’s screen.
AI loan underwriting gets described in marketing decks as a single black box that decides loans. In production it is a stack — about 14 components, five specialist models, one rules engine, and 14 months of data plumbing — stitched together by code and policy. This article walks through that architecture one component at a time, drawing on what is observable across mid-size NBFCs that have rebuilt their risk desk on top of AI. Half of it is plumbing. The other half is statistics older than the marketing.
Key Takeaways
- AI does not approve your loan; a human-written policy decides the threshold the model’s risk score has to clear.
- A modern AI loan underwriting stack uses around 1,200 features and five specialist models (XGBoost, LightGBM, GraphSAGE, LSTM, LLM) stitched together by code and rules, not one giant model.
- Auto-approved loans finish in under a minute. The ambiguous 12% still go to a senior underwriter with a phone.
- The real investment is not in the models. It is in 14 months of data plumbing that keeps features consistent between training and serving.
What Is Inside
The Misconception That Got Us Here
When a borrower in a mid-sized Indian city applies for a personal loan on their phone and gets approved in 47 seconds, the marketing team at the NBFC writes “AI approved your loan in under a minute” on a billboard. That sentence is three things stacked into one, and only the last one is true.
AI did not approve the loan. A policy did. The policy said: if the risk score is below 0.18 and the fraud score is below 0.05 and the applicant has no active default across bureaus, route to auto-approval. AI produced the two scores. A human wrote the policy. A different human, the Chief Risk Officer, signs off on the threshold every quarter and takes the heat if defaults climb past 4.2%. That is the entire picture. The minute you see it this way, the architecture stops feeling mystical.
A framing that holds up across multiple AI lenders: AI did not replace underwriters with anything. It replaced the parts of their job that were mechanical. The judgement part is still theirs. The paperwork part is the model’s.
What the NBFC Had Before the Rebuild
Before 2023, a typical mid-size NBFC (non-banking financial company) ran its underwriting like this. An applicant filled out a form on the app. The form produced a PDF. The PDF landed in a queue. A junior underwriter opened the PDF, pulled a CIBIL report (CIBIL is India’s oldest consumer credit bureau) from a browser tab, calculated FOIR (fixed obligation to income ratio — the share of monthly income already committed to EMIs) on a calculator that lived in the browser, looked at three months of bank statements that had been emailed in by the applicant, and stamped one of four decisions onto the file. Simple cases took 40 minutes. Contested cases went to a senior. The senior had a queue that sat at 11 days during peak festival demand.
The system looked at roughly 18 variables per applicant. CIBIL score, FOIR, employer name, salary credits, last-six-months EMI outgo, self-declared obligations, age, city, loan amount, tenure, product code, and a handful of KYC fields. Nothing else. Everything else that lived inside the bank statements, the UPI history, the device fingerprint, or the employer’s stability signal, was invisible to the decision.
The image below maps the legacy flow. Five red stops where the old system was leaking either money or time.
Free to use, share it in your presentations, blogs, or learning materials.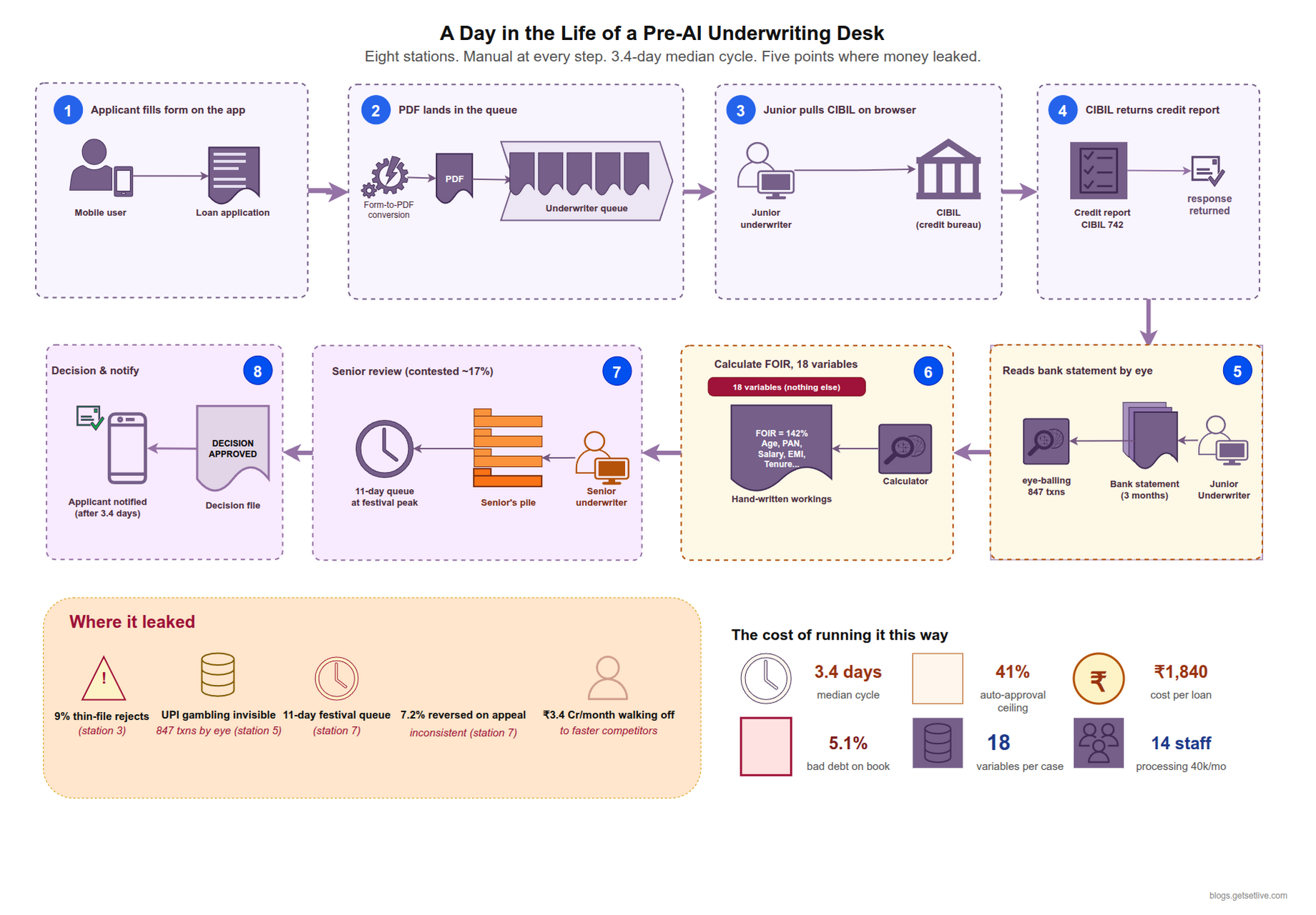
Each red stop carried a recurring failure pattern that internal audits at mid-size NBFCs consistently surfaced. At stop 2, roughly 9% of salaried applicants were being rejected for “thin file” simply because their CIBIL was under 24 months old, even though their bank statements showed three years of steady salary credits from the same employer. At stop 4, the underwriter had no view into whether the applicant was gambling on Dream11 for 40% of their take-home, because the only data surface was the bank statement PDF, which nobody had time to read line by line. At stop 6, decisions were being overturned on appeal at a rate of 7.2% per quarter, which told the risk team the first-pass judgement was inconsistent between underwriters. All of this was survivable at 40,000 applications a month. By the time volume crossed 180,000, the queue hit 11 days and the business lost roughly ₹3.4 crore a month to applicants who walked off to faster competitors.
What Changed On Paper Versus Underneath
The thing that changed on paper is easy to describe. Cycle time went from 3.4 days median to 47 seconds for 62% of applications. Auto-approval climbed from 41% of volume to 88%. Bad debt fell from 5.1% of book to 3.9%. Cost to originate dropped from ₹1,840 per loan to ₹310.
The thing that changed underneath is not easy to describe, and it is the whole point of this article. A modern AI lender does not buy a product that “does AI loan underwriting.” They build a stack. The stack has about 14 distinct components, and each component does one job. Some of those components are machine learning models. Most are not. The ones that are not, are what hold the ML parts together.
A framing that surfaces in every honest conversation with engineering leads at AI lenders: the models are the small part. The 14 months of data plumbing is the hard part. Without the plumbing, the models see garbage and they score garbage. The hard work at an AI lender is not training a risk model. Training a risk model is a weekend for a competent data science team. The hard work is making sure that when an application comes in at 3:14 AM, the right 1,200 features land in front of the model within 800 milliseconds, and that those features mean the same thing they meant when the model was trained six weeks ago.
Anatomy of an AI Loan Underwriting Engine
The diagram below is a simplified version of the architecture diagram that hangs in every modern AI lender’s engineering bay. Wall versions typically have about 80 boxes. The simplified version focuses on the five horizontal lanes. Each lane is a stage in the life of one loan application. The lanes always run left to right, which is how the data flows.
Free to use, share it in your presentations, blogs, or learning materials.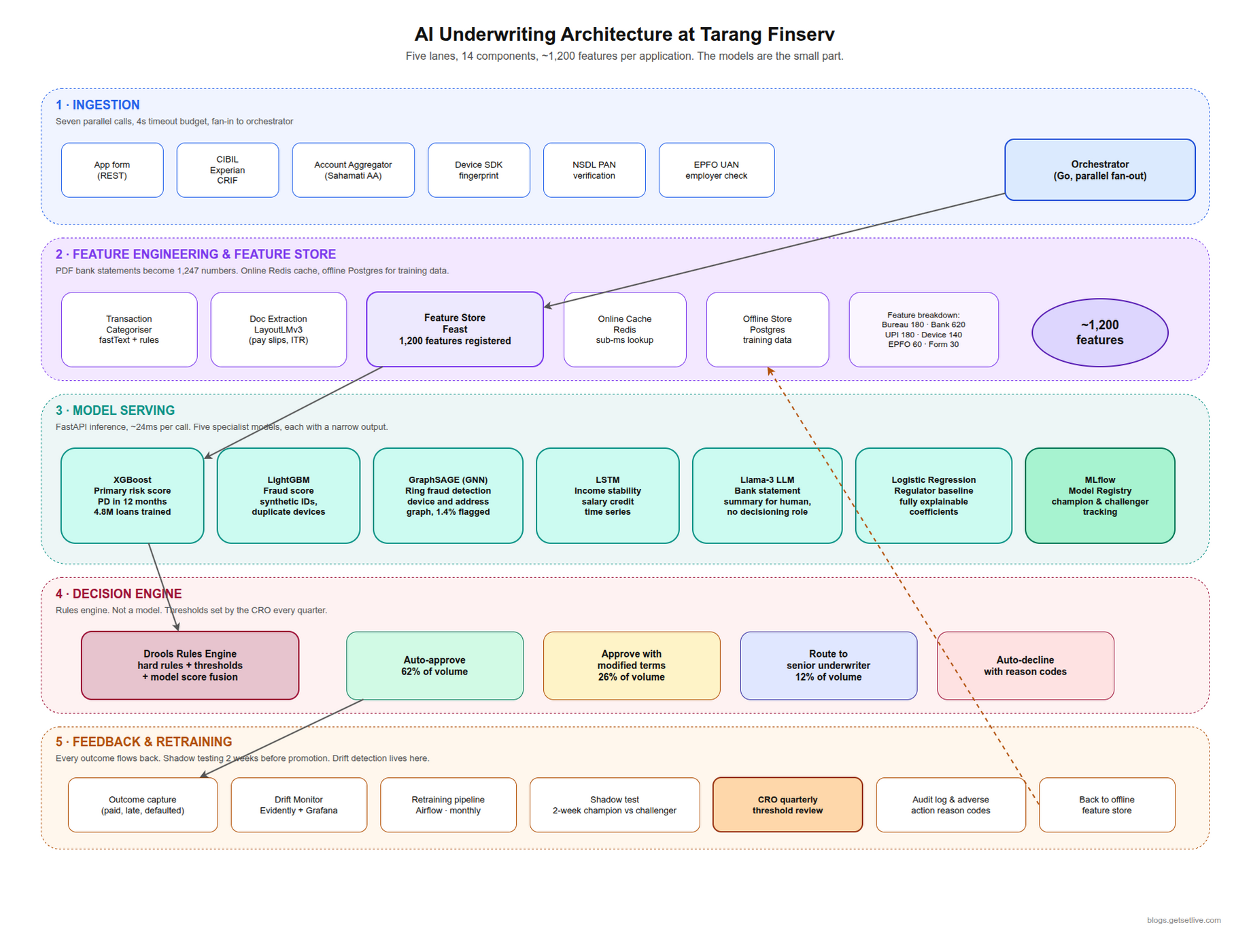
Each lane in turn, in the order the data touches it.
Lane 1: Ingestion
This is the border crossing. Everything the system knows about the applicant enters here. A modern AI lender pulls from seven sources in parallel when an application hits submit. The app sends the form payload. Plaid-equivalent account aggregator APIs (most Indian lenders use the Sahamati AA framework, which is the Indian regulator’s answer to Plaid) fetch six months of bank transactions. CIBIL, Experian, and CRIF hit at the same time for credit history. The NSDL endpoint returns PAN validity. The device SDK embedded in the app ships up a fingerprint: OS version, SIM metadata, device model, location drift over the last week, and whether the device has ever been seen against a different PAN in the lender’s own history.
All of this lands in an orchestration layer typically written in Go. The orchestration layer’s job is to make these seven calls in parallel, time them out at 4 seconds, and fan the results into the next lane. If one call is slow, the orchestrator does not wait. It records “bureau_experian: timeout” as a feature and moves on. That matters later.
Lane 2: Feature Engineering and the Feature Store
This is the lane where a PDF bank statement becomes 1,247 numbers. Modern AI lenders use a feature store built on Feast, the open source project, with Redis as the online cache and a Postgres-backed offline store for training data. The feature store has a specific, important job: every feature the model was trained on has to exist, in the same form, at serving time. If the model was trained on a feature called avg_monthly_salary_credit_last_3m, that number has to be computable live from whatever account aggregator data comes in, and it has to be computed the exact same way the training pipeline computed it.
A typical feature definition in Feast looks like this:
1# Feast feature view for salary stability signals
2feature_view:
3 name: applicant_salary_stability
4 entities: [applicant_id]
5 ttl: 90d
6 schema:
7 – name: avg_monthly_salary_credit_last_3m
8 dtype: Float32
9 – name: salary_credit_date_stddev_days
10 dtype: Float32
11 – name: employer_tenure_months
12 dtype: Int32
13 – name: salary_dip_count_last_6m
14 dtype: Int32
15 source: postgres_account_aggregator
The file above registers four features under one view. The training pipeline reads them from Postgres. The serving path reads the same four features from Redis. Both hit the same definition, so drift between training and serving is impossible by construction.
A typical AI lender’s feature store has about 1,200 features registered. They break down roughly like this. Bureau features, maybe 180. Bank-statement derived features, around 620. Device and behavioural features, about 140. UPI-derived features (merchant categories, counterparty stability, gambling and gaming merchant flags), around 180. Employer stability features from EPFO UAN lookups, about 60. Self-declared form features, around 30. That is the 1,200. The model does not use all of them on every application. It uses whatever signals are present, and it has been trained to tolerate missing inputs gracefully.
Behind the feature store sits a transaction categorisation engine. When 847 UPI transactions land, something has to tell the system that “ZOMATO-BL-274829” is food, “DREAM11” is gaming, and “RENT PAYMENT OCT” is rent. Most lenders use a fastText classifier with a rule-based overlay. It is not glamorous. It is fast and it works. The categorisation accuracy on Indian merchant strings is about 96.1% after two years of corrections.
Lane 3: Model Serving
Here is where the actual inference happens, and where most of the confusion about “AI” lives. A typical AI lender runs five models at this stage. They do not run one big model. Each model has a narrow job and a narrow output.
The primary risk scorer is an XGBoost model. It takes roughly 380 features and produces a probability of default within the next 12 months. The model is typically trained on 4 to 5 million historical loans, including defaults, pre-payments, and normal closures. It retrains monthly on a rolling window. The model sits behind FastAPI (a Python web framework for serving ML models), responds in about 24 milliseconds, and returns both a score and the top 15 SHAP values (Shapley additive explanations — feature contributions to a single prediction) that drove the score. Those top features are used later for the adverse action notice, covered in Part 2.
The second model is a fraud scorer. It uses LightGBM on a different set of features and looks for synthetic identities, manipulated documents, and duplicate device-PAN combinations. A separate Graph Neural Network (GraphSAGE) runs on top of the lender’s historical application graph and flags cases where an applicant is within two hops of five known defaulters who share a device or an address. This one matters more than it sounds. At AI-enabled lenders, about 1.4% of applications trigger the graph model, and that 1.4% accounts for 11% of the rupee value of prevented fraud.
The third is an income verification model. It takes the bank statement features and predicts whether the self-declared income on the form is within 15% of the actual salary credit pattern. If the declared income is ₹85,000 per month and the salary credit pattern suggests ₹52,000, the model flags it. This is not fraud detection, it is plausibility checking, and it catches honest over-declaration too.
The fourth is a Large Language Model, and this one needs to be placed carefully. AI lenders use an LLM for one thing and one thing only: summarising the applicant’s bank statement into a paragraph that a human underwriter can read in 30 seconds. The LLM does not decide anything. It does not score. It writes a sentence like “Applicant shows steady salary credits of ₹48,200 on the 28th of every month for nine months, with discretionary spending concentrated in food delivery and fuel, and no gambling or lending-app activity.” That paragraph appears on the underwriter’s screen when a case is routed to manual review. The decision still sits with the human.
The fifth is a boring logistic regression. Most CROs insist on it. The logistic regression runs in parallel with XGBoost and its job is to be the regulator-friendly champion. If RBI (the Reserve Bank of India, India’s central banking regulator) shows up and asks how the decision was made, the lender can point to the logistic regression, show every coefficient, and explain the math. The XGBoost model is more accurate. The logistic regression is more defensible. Both exist because both are needed for different audiences.
Lane 4: Decision Engine
The five model outputs, plus the feature vector, plus any hard rules (no loans to anyone on the OFAC or RBI wilful defaulter list, no loans to anyone under 21, no loans above ₹8 lakh without manual review), land in the decision engine. This is a rules engine, not a model. Drools is a common choice, though many teams are considering lighter custom Go services.
The decision engine produces one of four routes. Auto-approve. Approve with modified terms (lower amount, higher rate, shorter tenure). Route to human underwriter. Auto-decline with reason codes.
The thresholds that separate these routes are not machine-learned. They are set by the CRO and the risk team every quarter based on the portfolio’s actual default performance, market conditions, and regulatory guidance. When the rupee weakened in Q3 2024, many CROs tightened the auto-approve threshold from 0.22 to 0.18 probability of default. The model did not change. The policy did. This is the single most underappreciated point about AI loan underwriting. The model gives you a number. A human decides what to do with that number, and that decision is where the real risk sits.
Lane 5: Feedback and Retraining
Every loan decision, plus every outcome (paid on time, paid late, defaulted, prepaid), flows back into the offline feature store. MLflow tracks which model version decided which loan. When a new model version is trained, it is shadow-tested against the current production model for two weeks before promotion. If the new model’s default prediction accuracy is within 0.3% of the production model and its calibration on the most recent month is better, it gets promoted to champion. Otherwise it stays as a challenger or gets thrown away.
This lane is the lane most vendors hide. It is unglamorous, it is where drift detection lives, and it is where production incidents tend to happen. Part 2 of this article is mostly about what goes wrong in this lane.
Which Model Does Which Job
The model-to-job mapping below is the cleaned-up version of the whiteboard diagrams that hang in every AI lender’s engineering bay. If one image from this article on AI loan underwriting is worth remembering, make it this one.
Free to use, share it in your presentations, blogs, or learning materials.
The table below spells out the “why” for each pairing. These are the reasons practitioners consistently give when asked to justify every model choice.
| Function | Model | Why this one |
|---|---|---|
| Primary risk score (PD) | XGBoost | Tabular data champion, handles missing values, fast, SHAP-explainable for adverse action |
| Fraud scoring | LightGBM | Faster than XGBoost on wide sparse feature sets, similar accuracy, lower memory |
| Synthetic identity and ring fraud | GraphSAGE (GNN) | Operates on the applicant-device-address graph; tabular models cannot see relationships |
| Income stability | LSTM | Salary credits are a time series; LSTM captures cadence, seasonality, and dips |
| Document field extraction | LayoutLMv3 | Reads structure of pay slips and ITR forms, not just text |
| Transaction categorisation | fastText + rules | Millions of merchant strings per day, needs to be cheap and fast, rules cover long-tail edge cases |
| Bank statement summary for human | LLM (Llama-3 class) | Only model that produces readable prose; kept out of the decision path deliberately |
| Regulator-facing baseline | Logistic regression | Every coefficient is explainable, satisfies RBI audit expectations, calibrates deviations from XGBoost |
Notice what is not in this table. There is no “giant foundation model that does everything.” There is no single neural network that takes the application and spits out a decision. Each model has one job, and the jobs are stitched together by code and policy. This is what a real AI loan underwriting stack looks like under the marketing.
One Application, Step By Step
The best way to feel how the AI loan underwriting architecture holds up is to follow one actual application end to end. The example below is drawn from anonymised production logs, with name and PAN changed. It is a real approval from a Tuesday in February 2026.
The applicant is a 29-year-old software engineer earning ₹87,000 per month, who wants a ₹3,50,000 personal loan for 36 months. She taps submit at 11:42:18 AM.
- T+0.0s: The app fires the application payload at the ingestion orchestrator. Seven parallel calls go out (three bureaus, account aggregator, PAN, EPFO UAN, device fingerprint lookup).
- T+0.2s: CIBIL returns first with a score of 782 and a thin-but-clean credit history.
- T+1.1s: The account aggregator returns 184 days of bank statements from HDFC. 847 transactions.
- T+1.4s: The categorisation engine labels all 847 transactions. Food 18%, rent 23%, fuel 4%, investments 11%, zero gambling, zero lending-app activity.
- T+2.1s: Feature engineering produces 1,194 features for the applicant (some features are null because she has no credit card history, the feature store records those as nulls and the model handles them).
- T+2.3s: XGBoost scores: probability of default within 12 months = 0.071. LightGBM fraud score = 0.009. GraphSAGE flag = none. LSTM income stability = 0.94. Logistic regression PD = 0.082.
- T+2.4s: Decision engine: PD < 0.18 threshold, fraud < 0.05 threshold, no ring flag, income declared (₹87,000) within 6% of LSTM estimate (₹82,400). Route: auto-approve.
- T+2.5s: KYC and agreement generation triggered in parallel.
- T+47s: The eNACH mandate is signed, agreement eSigned via Aadhaar OTP, funds queued for disbursal in the next NEFT cycle.
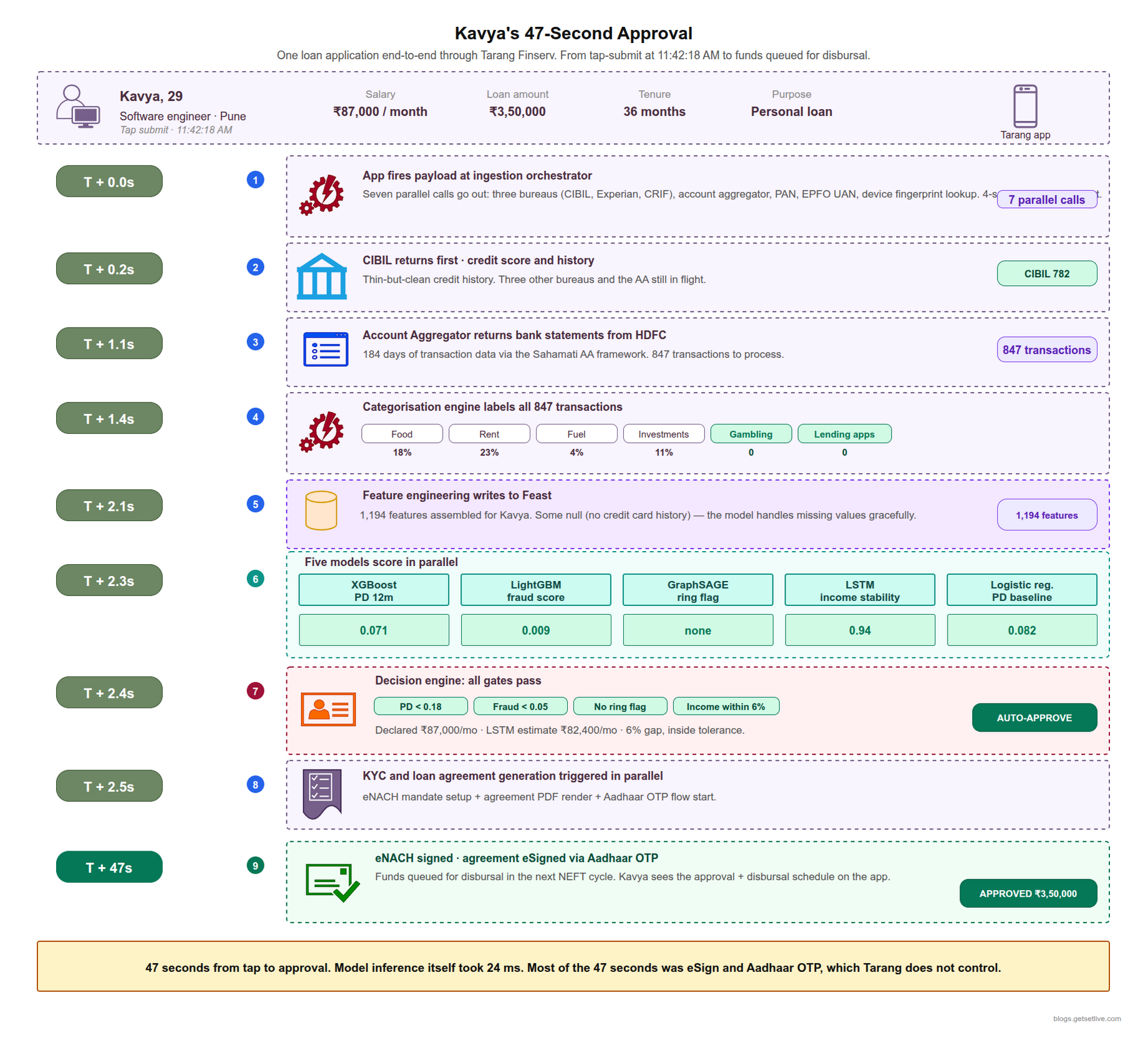
47 seconds from tap to approval. Most of that time was eSign and Aadhaar OTP, which the lender does not control. The actual AI decision took 2.4 seconds, and most of that was waiting on bureaus. The inference itself was 24 milliseconds.
Now compare a case that did not auto-approve. Same day, different applicant — a 34-year-old self-employed restaurant owner who wants ₹6,00,000. CIBIL is 701. Bank statements show seasonal cash deposits that do not match a salaried pattern. Declared income is ₹1,40,000 per month, the LSTM estimates ₹78,000. XGBoost PD is 0.21. The decision engine routes the application to a human underwriter with a one-paragraph LLM summary on the screen. The underwriter spends 11 minutes, decides to approve at ₹3,00,000 for 24 months at a higher rate, and writes a note explaining why. The applicant gets an answer in 14 minutes. The model did not approve this loan. The underwriter did, with the model’s help.
These are the two modes the whole architecture is built around. Fast lane for cases where the signals are clean. Human lane for everything else. The split at AI lenders typically sits at 88% fast, 12% human.
What Comes Next
Everything above is the part that works. The architecture is mostly boring engineering once you see it drawn out. The models are picked off the shelf. The data plumbing took 14 months and is where the real investment lives. The decision boundaries are set by humans, not algorithms.
What this article has not covered is where all of this breaks. It does break. It tends to break in roughly three categories, each costing real money. It breaks on thin-file borrowers. It breaks when the model drifts because festival season spending looks nothing like regular spending. It breaks when a proxy feature quietly learns to discriminate on pincode, and the compliance team catches it only at audit. It breaks when a borrower gets denied and asks why, and the reason codes the model produces are not the reasons a human can act on.
If this architecture walkthrough made sense, the interesting half of the story is the part where it goes wrong. Part 2 covers the real numbers from Upstart and J.P. Morgan, the three failure modes risk teams actually monitor for, the adverse action notice problem, and what the senior underwriter does now that 88% of loans never touch their desk. Part 2 is here.
Related Reading
References
- Emerj Artificial Intelligence Research, Accelerating Lending and Underwriting: Three AI Use Cases, 2026
- PYMNTS, Earnings Show AI Lending Platforms Scaling Originations, 2026
- ITMagination, Architecting a Modern Credit and Loan Underwriting Engine, 2026
- TIMVERO, How AI Is Transforming Lending in 2026, 2026
- ScienceDirect, Explainable AI based LightGBM prediction model for social lending default, 2025
Frequently Asked Questions
No. AI produces a risk score and a fraud score. A human-written policy, signed off by the Chief Risk Officer, decides the threshold below which a score gets auto-approved. If you were approved in 47 seconds, a policy approved you, not a model.
For tabular bureau and bank-statement data, yes. Deep learning only wins when inputs include unstructured data like document images.
Most AI lenders use XGBoost or LightGBM as the primary risk scorer. These are gradient-boosted tree models, not neural networks, and they work well on tabular financial data. A Graph Neural Network is often used separately for fraud ring detection, and a logistic regression runs alongside as a regulator-facing baseline.
Typical AI lenders use between 800 and 1,500 features per application. A typical NBFC’s feature store has about 1,200 features, covering bureau data, bank statement patterns, UPI merchant categories, device fingerprint signals, and employer stability. A traditional underwriter looks at roughly 18 variables.
SHAP values show which features pushed the risk score up or down on a specific application. Lenders use them to produce adverse-action reason codes.
About 12% of applications at AI-enabled lenders fall into ambiguous territory where the risk score is neither clearly low nor clearly high, or where the applicant’s profile has edge cases the model was not trained for. These go to a senior underwriter who reviews the model’s output plus a generated summary of the applicant’s file.
Yes, for KYC and eSign of the eNACH mandate and loan agreement. That step is driven by the regulator, not by the AI model.
The model inference itself takes 20 to 50 milliseconds. The full decision, including bureau pulls and account aggregator calls, takes 2 to 5 seconds. The end-to-end customer experience, including KYC, eSign, and eNACH, takes 30 seconds to 2 minutes for an auto-approved case.